 论文排版软件
论文排版软件两周前(2月25日),我在云自习室讲了一场分享会,“面向GPT的工作和学习”。学友们的评价还不错——
“榛子分享了很多’道‘层面的东西”,
“从思维层面入手来解决问题,就有以一驭万的感觉”,
“对我有很大的益处,无论是心理层面还是技术层面。很喜欢榛子从认知科学(cognitive science)的知识图出发,讲解如何用ChatGPT优化学习过程“
“榛子让我重新认识了GPT和个人知识体系搭建,发挥GPT最大作用为我打工,而不是仅仅当作检索工具或者担心自己被其取代“
……
本篇图文是这场分享会的”重新整理版”。
是当时那1.5小时语音分享会的补充,
也是下次在自习室再讲这个话题(预计三月底四月初)前留给参与者的”预习材料”。
-
时间:这篇真的太长了(2万多字,16张概念图,信息量巨大)。根据预览同学们的反馈,通常第一次阅读到Part 3时,会消耗很多精力,但读完发现Part 3是精华,也最烧脑。请大家酌情安排阅读时间,建议收藏。
-
可读性:我会在内容里邀请你一起思考(无需专业知识),所以可能不适合通勤时间阅读,也不太适合”听”。你的阅读收益取决于在过程中思考的参与程度。
-
适合人群:关心自己的工作会不会被AI代替的朋友、想借助AI的力量更好地思考和学习的朋友。
-
关于链接和参考文献:阅读本文时,无需阅读每个链接框里的内容,这并不会影响对本文的理解。
第一部分,我会从「术」的层面分析,如何引导GPT思考,解决我们的问题。没有”一个prompt让GPT的回答更好”这样的速成,我们只谈“如何思考”的方法论。
第二部分,我会从「道」的层面讨论,了解GPT擅长什么、使用的人类又擅长什么,培养和GPT的默契感,让每个人都能从容地驾驭这以一驭万的武器。
第三部分,我会从「法」的层面解析,(1) 如何让使用者和GPT都发挥最大价值,(2) 如何让新学到的知识能更牢固地扎在我们的知识框架中,(3) 如何用GPT提升输出的能力等等。
第四部分,我会「分享」自己和GPT-4这一年相处的点滴,我眼中人与GPT的未来。
另外,本文有英文版,发表在Medium。英文版的可读性更高些,全文只有约8k词,讲了同样的信息。推文最后,点击阅读原文可跳转到英文全文。

正文目录
-
引子:我与GPT-4的这一年
-
Part 1:GPT永远改变了“个人知识管理”
-
GPT到来之前的”个人知识管理”
-
GPT彻底改变了”个人知识管理”
-
Part 2:我们和GPT的”思考”有什么不同
-
人是怎么思考、理解新知识的?
-
GPT”思考”的时候在做什么?
-
Part 3:让GPT和人类发挥各自的最大价值
-
用GPT定制学习路径
-
用GPT提升encoding
-
用GPT提升retrieval
-
你的”笔记”,何须在”笔记”软件里进行?
-
用GPT提升”输出”的能力
-
Part 4: 人与GPT的未来
-
人类调用算力和存储手段的最终级形态
-
GPT不会毁灭全人类,它是人类文明的第二个“印刷术”
引子:我与GPT-4的这一年
我和我妈两个OpenAI账号,从2023年2月到现在,我为OpenAI交了整整480美元的学费。这可能是我这辈子最值的投资。
一年下来,GPT-4不但是我的同事、下属、老师,甚至很多时候还是我思想的投影。
正如iPhone已经成了我身体的一部分,是我看到并记录外界世界的眼睛、听到众生想法的耳朵……GPT-4也成了我身体的一部分。
它是我思考的辅助工具,极大优化了我的信息获取、科研、学习和工作的过程,也成了我身体的一部分,我的器官——第二个大脑。
我把一些低层次的检索和思考工作外包给它,让自己能一直处于更高层次的思考和创作中,沉浸于”心流”。
GPT还让我重新思考我的本职工作:怎样的DS/SDE才是不可替代的?哪部分的工作属于搬砖?哪部分是在创造价值?
借助它的力量,去追求更高效地工作,更广泛地外延,更深度地思考。
最后,更短的工作时长,做多好几倍的事情。
这篇文(以及云自习室的“分享会”)就展开说说, 我给Open AI交的学费学到了什么,这一年“面向GPT的工作和学习”的心得。
还有一些写在前面的备注:
1. 我近期也开始使用Claude-3,并与GPT-4进行了对比。本周三和周四,云自习室的分享会上,我会和学友们探讨这两个AI的智能与极限。
2. 自OpenAI开放付费以来,我未再使用3.5版本,也不使用Bing。试验过Google的LLM,但感觉不够智能。虽然本文的举例专注于GPT-4,但所写内容与思维方式经得起时间考验,不受所选LLM模型影响。
3. 本文提到的所有与GPT的对话都是英语,但为了阅读方便,会将要点翻译成中文呈现。有些很难准确找到中文对应词的部分依然用的英语(为不喜欢读双语夹杂的朋友提前道歉)。
4. 想参与云自习室分享会的朋友们,可以加入我的Discord云自习室:https://discord.com/invite/8aprmSqxvw 。云自习室免费,分享会也免费 (使用自习时长得到的金币就能兑换分享会的门票)
正文开始了👇
Part 1
GPT永远改变了“个人知识管理”
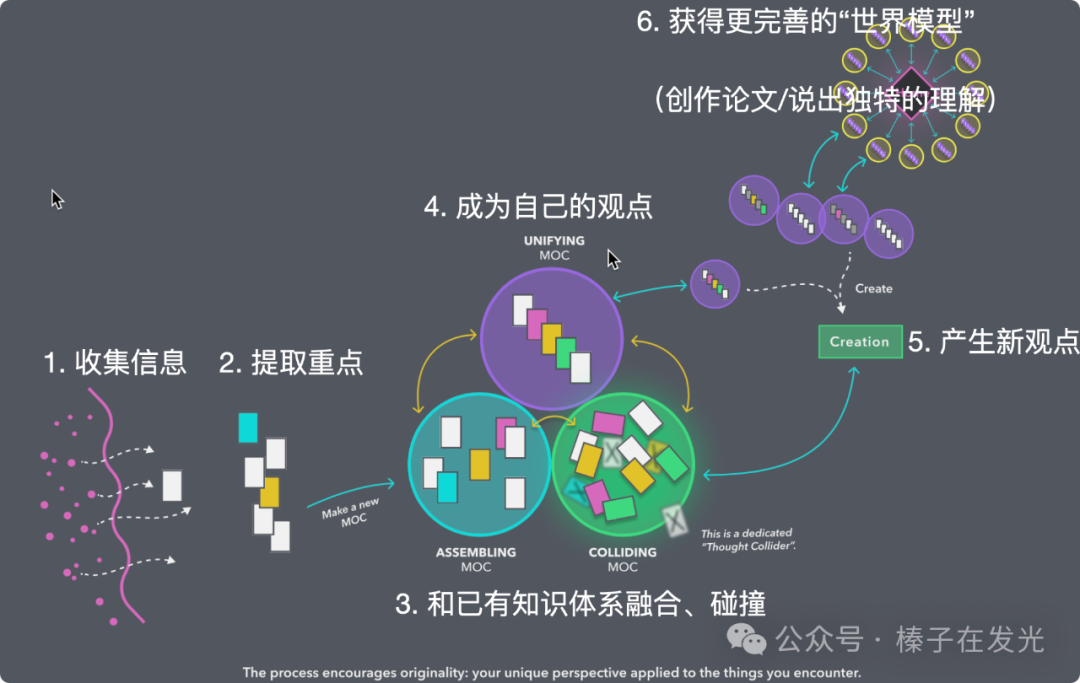
1. 收集相关信息:建立一个知识框架或学习路径图,开始阅读和学习的过程
2. 划出其中重点:处理新知识,从中汲取出此刻最在意的重点信息
3. 融入世界模型:让新来的知识能融入现有的知识体系里,去解决我们的问题(暂时叫它”世界模型”)
4. 输出我的观点:在面对需要用到对应知识的场景时能够及时有效地从脑中提取并有效输出(考试、写论文、汇报、与人交流…能输出有逻辑的话,有支撑的论文)
我们叫这个流程”个人知识管理“(Personal Knowledge Management,简称PKM)。
GPT到来之前的”个人知识管理”
2021年8月,我在云自习室围绕着”PKM”这个话题开了两期分享会。”道“的层面,是这样两张图,叫做”知识创造的时间和价值“(Time Value of Ideas)——
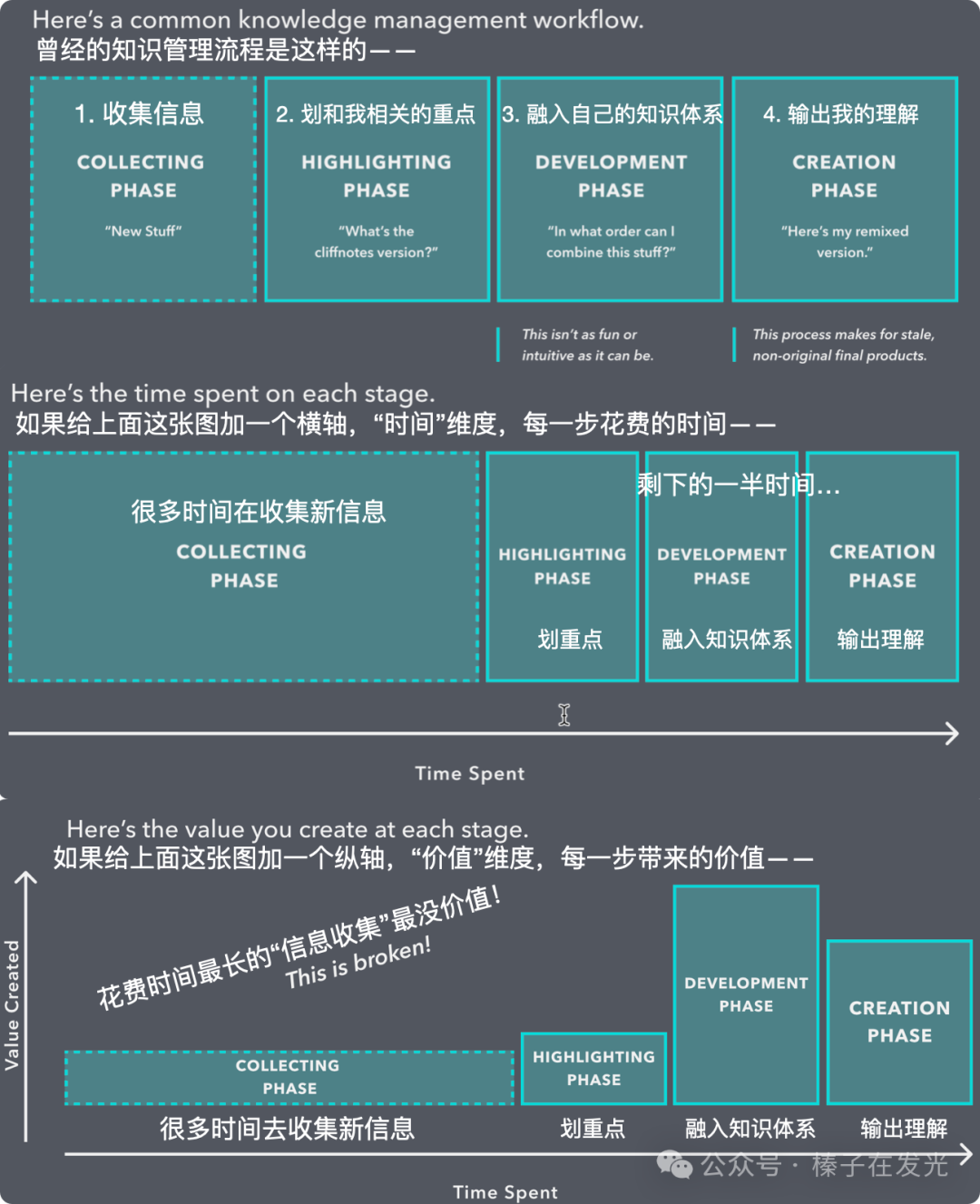
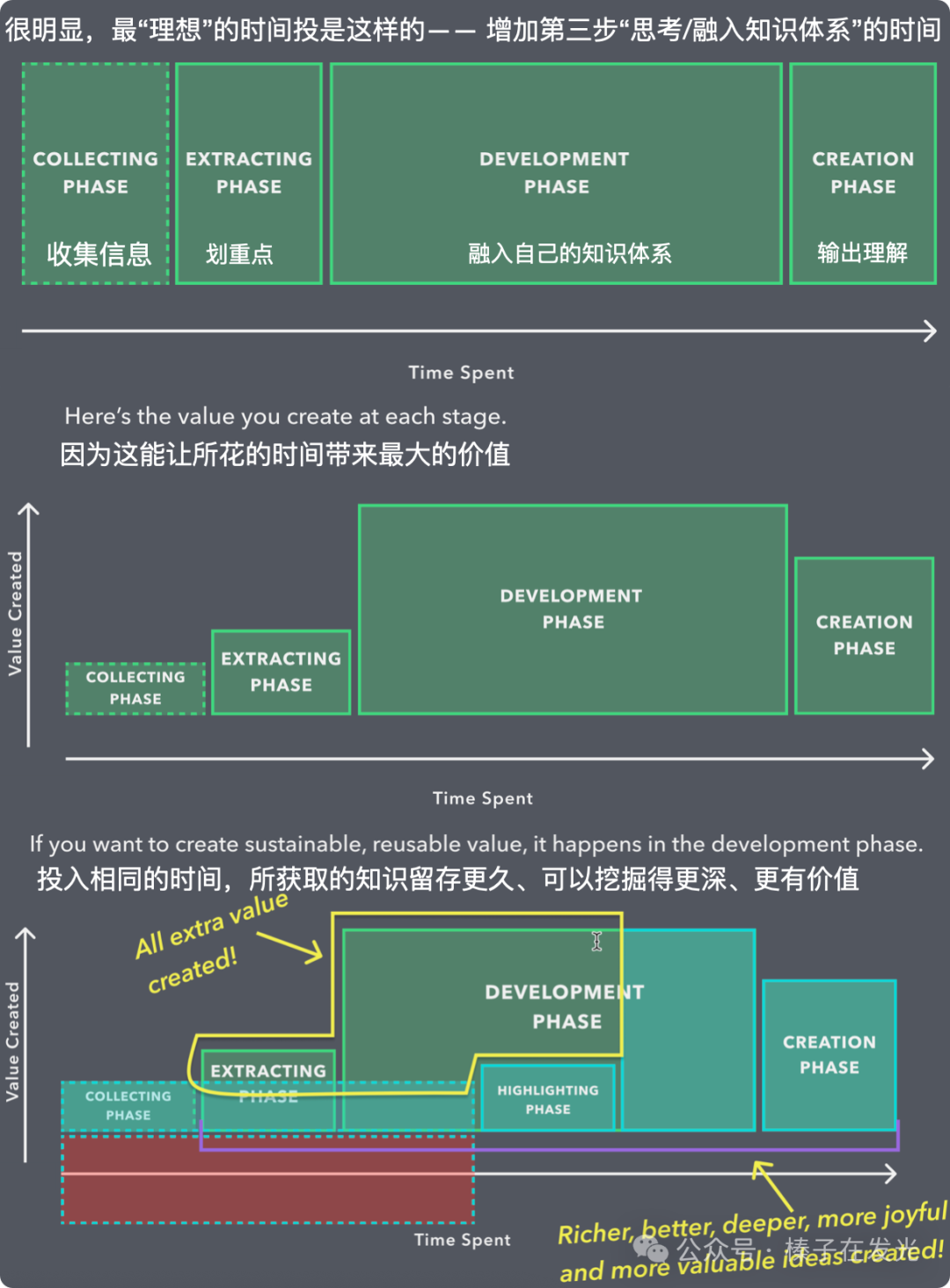
这两张图出自LYT Workshop,我是它很早期的学员。
现在这个Workshop的讲师在UCLA讲“知识管理”课程
科研中,常因感觉”所知不足”而心虚、不敢动笔,忙于表层工作:再看一篇我就写,再看一段我可能就懂了,再多划几条线吧…
然而,我们往往不是真的缺新信息。缺的是对已有信息的深度处理与整合,使其成为我们自身的一部分。
可能很多人都踩过这样的坑:
我要学…(新内容),花了三天收藏了好多教程,就没有然后了…
下载一篇新文章,犹如掉进了兔子洞——不断从引言、讨论、结论中挖掘出更多待读文献。每读一篇下载10篇,永远没有尽头…
读论文时随手就划线,到处都是重点。一个月后拿起读过的论文,思考当初为什么要划线强调。为什么我当时没有写一句话,哪怕一个词也好?之后,花费更多时间重读,试图找回划线时的思考脉络…
最后,看似读了很多、学了很多,但又好像什么也没有得到:依然没有自己的观点,写起论文依然困难。
我读博时真正”开窍”的过程是,某天起,规定自己读论文时必须也同时输出:如果要划线一句话,那我写的评论(comment)必须比这句高亮的话要长,并且在打字时就立刻用[[]]把它和我的PKM中其它那些相关概念都做好双向链接。
最后,导出所有论文对应的.md笔记到Obsidian,我想说的话、我的观点…便联结成了巨大的一张网。

我的Obsidian Vault里所有的笔记,从四年前第一次使用(有了第一个点),到如今有了五个清晰可见的“团”,几十万字的内容连接成了一个Knowledge network.

因为给自己规定过,收集观点时一定也要同时输出观点,所以这个知识库里至少一半的文字都是“我的想法”。利用这个知识库,写论文时便可以让自己的大脑始终处于“创作”模式。不必回去翻每个观点的原文出处——citekey和观点之间一对多的映射早在从论文批注中导出md笔记时便自动完成了。
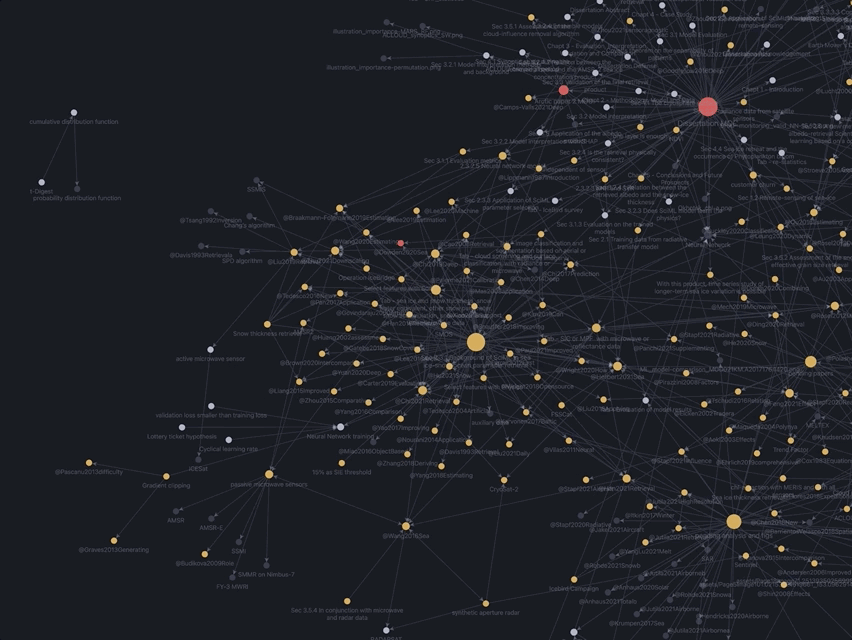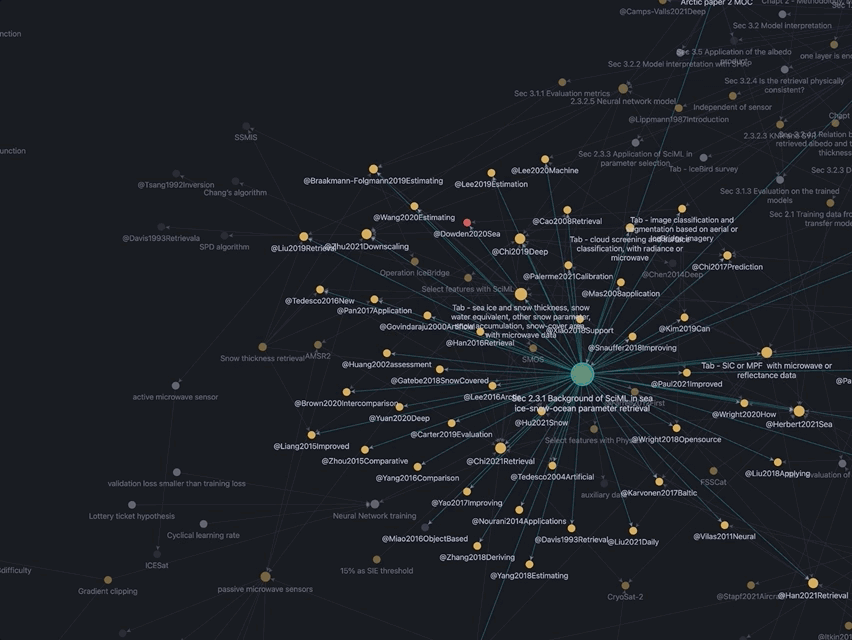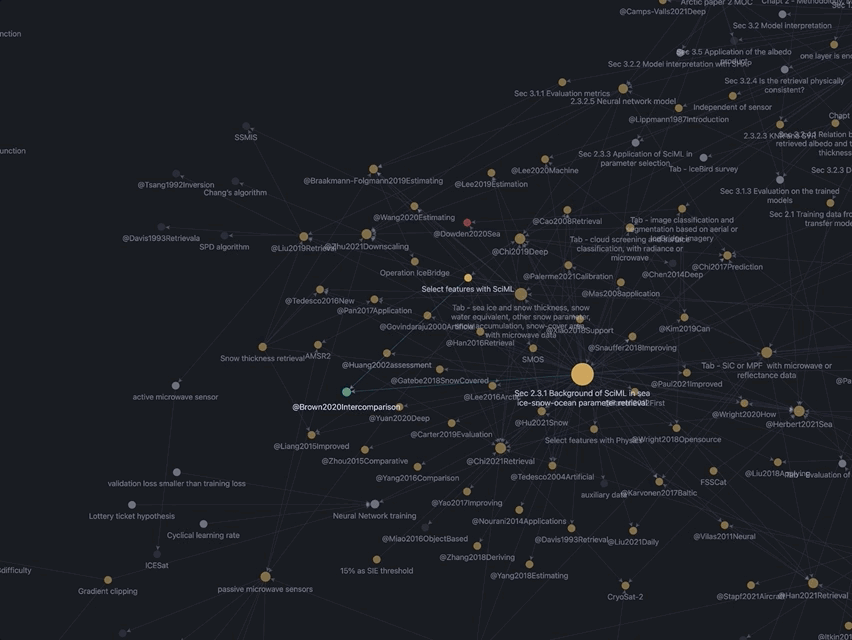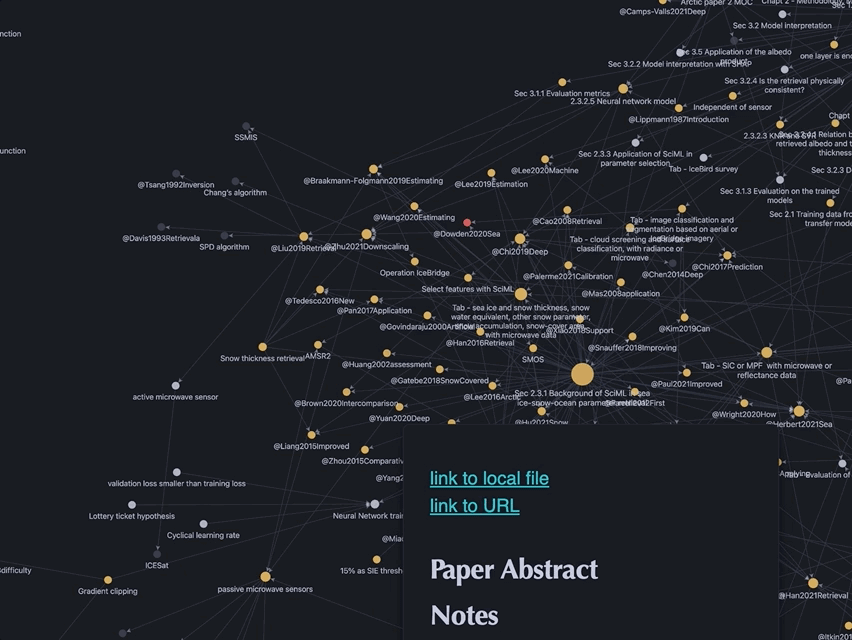
同样来自我的Obsidian Vault,这张Zoom-in的图聚焦在了博士论文的2.3.1小节,周围的小点就是写这一小节时引用的论文/观点、我的观点…
不必再发愁没有东西可以写。实在有太多可以写了:我赞成A,反对B,认为C站不住脚,觉得D这条路可以往下走,和E的研究有相似性,和FGHI用了相似框架却在xyz做出了改进…
那场分享会传递的主要信息是:将在”收藏网页”/”收集论文”/”无尽的搜索”/”给论文高亮划线”…中投入的时间最小化,把时间和精力都投入到第三步的 Development Phase。因为:
只有”和已有知识体系融合、碰撞,成为了自己的观点”,才能”产生新观点”,”获得更完善的世界模型”。

来自榛子的备注
对这一小节所讲内容感兴趣的朋友可以参考以下链接做拓展阅读/学习
1. 《How to Take Smart Notes》,从中学习Zettelkasten method
2. 连接主义(Connectivism)
Siemens, G. (2005). Connectivism: A learning theory for the digital age.
3. Vicky Zhao的这个播放列表
https://youtube.com/playlist?list=PLwLhCsXo_YKMfYMd8EVmL2g353cwAjSxl&si=92xWlWPWhRjGq3gD
4. 我未来还会继续讲“知识管理”的Workshop,带着练的那种。如果感兴趣,可以私信我。也可以持续关注公众号/自习室的消息。开课时火速来报名😉
GPT彻底改变了”个人知识管理”
回顾知识管理的过程,GPT在知识管理里可以发挥巨大价值:它无限缩短了”收集信息”的时间,甚至于我们可以完全不花费时间去收集信息,而只须利用好它的存在,”拿着答案找题目”。
比如,我有个项目涉及到要做针对时间序列数据做聚类(Time Series Clustering)。
GPT以前的时代,我需要 第一步,收集相关信息。
先利用这个关键词:
1. 搜其他的DS写过的Medium post
2. 找研究者们发过的相关论文
3. 去Github找相关的repository
第二步,划出其中重点:逐条读完,找到和我处理的问题最相关的那几个、细读。
结合我的问题去想”如何应用”,”是否合适”,”能不能用”…
第三步,融入世界模型。读文档,做归纳和总结,”搬运”来代码,用在项目中…
做完了,梳理一遍整个流程,找有什么漏洞,哪里假设没想清楚,哪里不够严谨。
安好心了再看结论,想它的价值,给领导的呈现方式。第四步,终于输出我的观点…
瞧,就是同样的四步。
1. 收集相关信息
2. 划出其中重点
3. 融入世界模型
4. 输出我的观点
这次的例子,”融入世界模型”这一步更复杂些(科研的例子其实比它还复杂,上一小节刻意做了简化)。
走一步,再看下一步。一切顺利的话一周做完。但更有可能的是:一条路走到头后发现其中某步不合适,推倒重来一遍、两遍、三遍…
而GPT的时代,面对同样的项目,我所需要的只是“在每个阶段都沿着思考路径一直往下走,并在每个阶段问出正确的问题”。
把思考留给自己,把执行留给它。
把评估和规划留给自己,把搜索留给它。
思考并提问。只要问对问题,就成功了大半。
不过,我这里的”如何提问“和你平时听到的prompt engineering不太一样。对于大多数人的使用来说,真正需要的只是一个信息完整的prompt。
讲到这里,可能已经有读者在脑补——那就问ChatGPT “如何做时序的聚类”(How to do time series clustering)?
这不够好。
那,”要做时序的聚类,有什么算法“(What are the algorithms that can be applied for time series clustering problems)”?
多了一些信息(这次的侧重点是”我要找的是一个「算法」”),但依然不够好。因为这不是”信息完整的问题”。
用户每次的提问背后,GPT并不真的是在”搜索”,把它当搜索引擎用就屈才了。
(我会在后文展开它究竟在做什么,暂时用”思考”这个拟人化的词替代GPT每次交互背后的过程)
你的GPT会怎么”思考”,80%以上都可以归因于”用户在引导它这么思考“。
那什么是一个“信息完整的问题”?
是带着「我」完整思路(thought process)的问题陈述。我在让解决问题的它(GPT)和我的思维同步,让它和我去想一样的问题,顺着我的思路去检索。只有这样才能获得我真正想要的信息。
-
我为什么要强调这是个”时间序列“的聚类?——因为我相信”时间”这个维度的信息是需要被利用到的,这才是关键。
-
我对于”聚类”的认识是怎样的?我需要GPT帮我理解”聚类”吗?——不需要,我知道K means或DB Scan并不能解决我的问题。它不需要回忆这些,更不需要给我提供相关信息。
-
我的问题是什么?是什么引导我想来找”时间序列的聚类”?——我确定我的时序有某种聚类规律:比如,面对2020年的公共卫生事件不受任何影响的划在一类、受了很大影响的划在一类、有很强季节性(yearly/monthly/weekly seasonality)的划在一类、受过一些影响但却回归甚至突破历史新高的划在一类…
-
还有哪些额外考虑的内容(constraints)?——如果同样是「受到公共卫生事件影响了」,那么我认为事件发生的时刻本身不重要,只有受影响的幅度重要。比如,3月跌幅20%和2月跌幅20%就该在同一个类(cluster)里;还有,我有成千上万个时序数据,我能用的CPU/GPU大概是x,这也是需要考虑的信息。
所以,信息完整的问题是: I now have ~3000 time series segments, and I’m pretty sure they can be clustered to some groups based on the trend / shape / troughs and peaks. I’m familiar with regular clustering (e.g. K means, hierarchical, DBSCAN), but none of them leverage the time dimension. With decent memory size, what else can I do?
回过头看,“有GPT之前”和”之后”,知识获取和管理的区别是什么?
此前,PKM的三步是完全割裂的。只有先做好了1和2才能做到3和4。
而如今,通过做到”明确需求的本质、提出信息完整的prompt”,其实就等于做到了PKM的前三步:
1. 收集相关信息:这个世界上肯定有无数人面对过相似问题,他们已经把”基于时序的聚类”研究得透透的,我不需要造轮子,只需要找到正确的轮子
2. 划出其中重点:描述清楚我的问题(车型),让GPT帮我找到哪些轮子可以匹配这个问题、让我了解装上轮子后这辆车可以发挥出的效果。我只需要顺着它继续去划重点,找到「能达到我想要效果」的轮子
3. 融入世界模型:在明确需求的过程中,我已经在一点点透露我的”已知”和”求”以及我的一部分”隐含假设”了。在之后和GPT的交互,只需要根据它的回答进一步缩小求解的范围,让答案能完美融入进问题模型/世界模型中去。
接着,GPT给我的8条建议,它已经划好了重点(第二步)、也在试图帮我融入问题模型(第三步)。





上下滑动查看更多
但这件事没完。
只要你的思考没有停下,问题就不该停下。
1. [根据它回答中引出的新名词追问]. 什么是”scale-invariant distance measure”?我的理解是…如果真是这样,那它就很适合…,那我的理解对吗?
2. [评估和比较,选择更合适我问题的方案]. 看起来DTW和K-Shape都很适合我的问题,因为前者可以…后者可以…如果我的最终目标是…,这两者有什么优劣?分别可以调用哪个package(我得真的能用上这个轮子)?
3. [问自己,同时也可以看看它会不会给我更好的灵感]. 如果用K-Shape,还需要提前对数据做哪些预处理吗?它既然已经scale invariant了,也就不用做scaling了?
这一系列的交互后,已经基本决定了方法,也就获得了一部分第四步”输出我的观点”的答案:我选择K-Shape是因为它…。
接下来只需要把项目从头到尾规划完整、执行了。只要每一步清晰可见、逻辑连贯,GPT去执行我的步骤一定比我亲自去”搬砖”来的更好。
(此处省略让它生成对应代码的问题)
不用去记住每个syntax,不必费劲匹配每个类型,省了去读文档一一找对应的时间。
可以用自己的脑力去规划、思考那些更有价值的问题:
-
怎么让这个过程更好地在未来被复现?我可能不止这一个项目需要用到它。
-
分配到的内存够处理的上限是多少个时序?如果不够用了,如何在分布式的机群实现这个算法?
-
假设聚类完了,带来的价值是什么?可以拿聚类后的标签结合输入数据做哪些事?
-
该如何和我的领导(一个不懂统计/算法/DS/tech的人)解释这个算法?
-
还有哪些组可能也会想用这个算法?能给他们带来哪些价值?该怎么说服他们也来用?
问自己每个问题,对于”明确执行步骤的”,直接向GPT提对应的需求——
-
为了更好的调用,请帮我封装到一个类(Class)里,这个类里应该有这几个函数(methods): name_1, name_2, name_3。
-
你先写一下函数名、变量和对应的docstring,我看看是否合理
-
看着不错,现在请逐个补充完整每个函数,从第一个开始…或者,第三个不对,这里应该用一个staticmethod,因为以后可能还要用它来…你可以再添加一个有下划线版的函数来调用staticmethod(或者反过来)
-
…
甚至在想清楚规划后,还可以和GPT讨论一番,看看它能不能激发出我的其他灵感——
-
我计划用它聚类标出的标签来做…,因为它解决了当下…的痛点。我觉得可能在…上也会有潜力,但还不确定往下…的问题怎么解决,我不成熟的想法是…,你怎么想?
-
我的领导是金融背景的,他应该知道K Means,我计划从这里切入给他解释了。有什么合适的比喻或解释方式可以让他更好接受K-Shape这个模型?
-
我们公司/组主要是做…的,我们一起头脑风暴一下未来还有哪些应用场景…我想到了…这能给他们带来的直接价值是…还有什么我可以做的?
在这个过程中,把GPT当下属、当同事,甚至当成自己的外置大脑,思维的投影。
和它建立一种默契:
给它上文、我脑中那些还不那么成体系的想法,它帮我想明白我到底在想什么、想强调什么、想找什么,把我需要的呈现出来。
这个过程就是传说中的“alignment”:对齐。
OpenAI里的开发者们在尽他们所能让GPT与人类的价值观更好的对齐(aligned),而我们作为使用者,为了发挥这个工具的最大价值,就要通过交互让GPT与我们的所思所想同步、对齐。
事实上,解决大部分问题,并不是靠”一个prompt让你的GPT的回答更好”的速成教程,或者是Github上的prompt外挂。
不需要人云亦云、也在你的问题前给GPT加一句”Please act as a Data Scientist and answer the following questions in a professional tone”,期待有了这个prompt之后,问原先那个”How to do time series clustering”的普通问题,GPT能突然开窍…
并不会。
骑同样的马,跑得快与慢,并不只取决于马,更多要看骑马的人。
你的GPT会怎么”思考”(并给出对应的回答),80%以上都可以归因于”用户在引导它这么思考“。
以上,是「术」层面的核心。
很多读者可能还有一系列的问题:为什么我的GPT没有你的好用?它胡编乱造怎么办?它生成的代码漏洞百出/它写的文字都是冠冕堂皇的废话我该怎么调教?
接下来,我们讨论「道」的层面,了解GPT擅长什么、使用的人类又擅长什么,培养和GPT的默契感,让每个人都能从容地驾驭这「以一驭万」的武器。

Part 2
我们和GPT的”思考”有什么不同
人是怎么思考、理解新知识的?
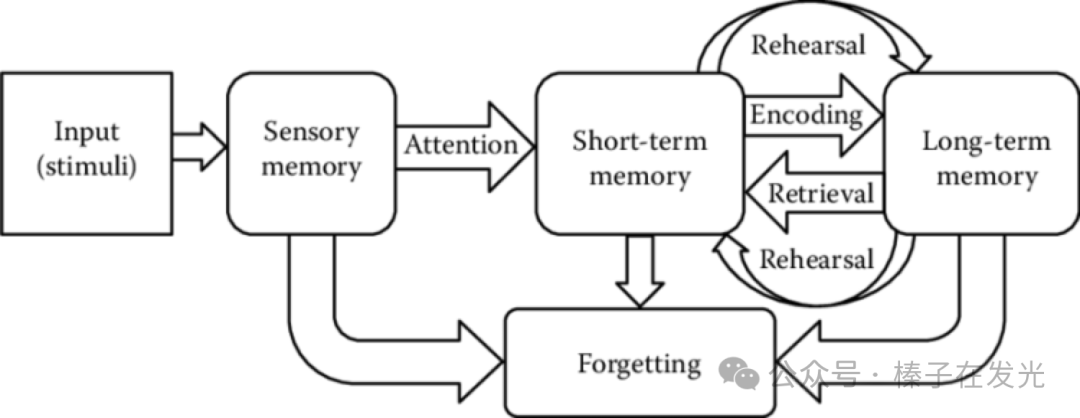
此刻,在逐行读这篇图文的你,眼睛接收到的信息(Sensory Memory)加上一点阅读时的注意力(”Attention”),图文的内容就进入了短期记忆(Short-term memory)。
如果此时我让你回忆上一个小节写了些什么,应该还是能回忆起几张图、几个步骤。如果一个月后再问,第一小节写了什么,你能从脑海中提取出来的信息(Retrieval)会越来越少。
但如果读的时候脑中做了进一步的信息加工。比如,结合着自己的经历、做了对比,获得了诸如「原来我的知识管理一直停留在信息收集和划重点,难怪输出时困难。这一点需要改正」的结论…或者,脑中闪过了「我不同意作者…观点」的反驳,这些思考加强了编码(Encoding)的过程,于是能留在长期记忆(Long-term memory)的部分就变多了。
在某些场景下,这些被编码收录进大脑的长期记忆就会被触发。
比如,看到一台钢琴——
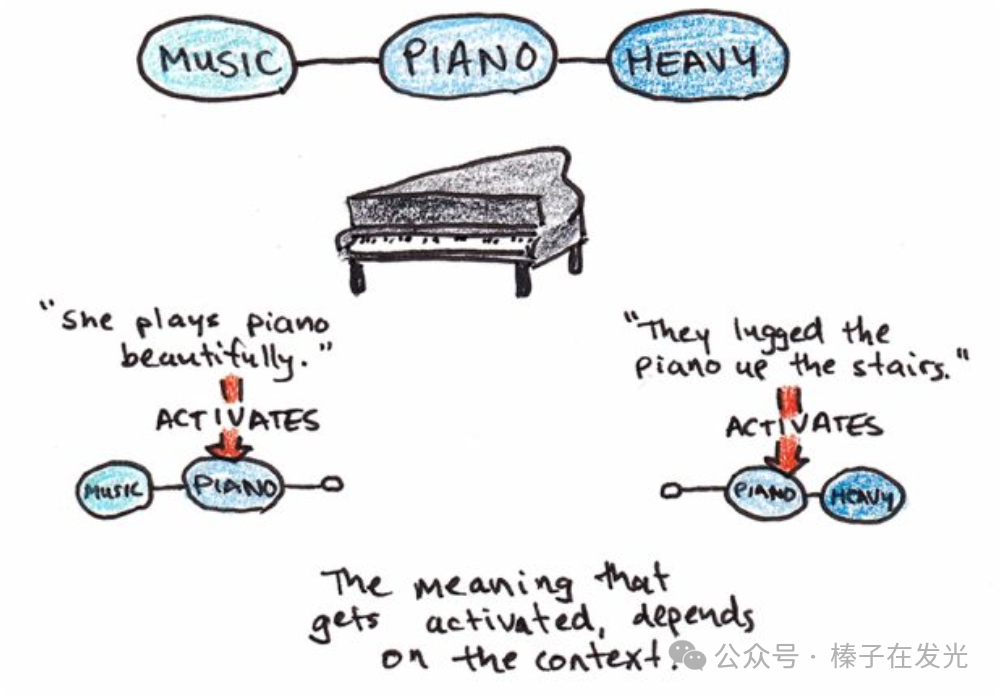
这张图出自Scott Young的博客,Scott Young就是那个“一年内自学完MIT四年CS本科课程”的Super Learner
可能会触发”钢琴声真美”,
也可能会触发”钢琴好重”。
Retrieval时想到的是哪一个,完全取决于retrieval时的场景和上下文(context)。
有了这个理解,很多问题也就有了答案

为什么初入一个领域、刚开始读书或者论文时会觉得”认知过载”(cognitive overload):

几乎所有的输入都是新信息,没有办法将其适当编码到记忆中与现有知识框架建立连接。新信息都不得不在只能保存几秒的短期记忆里,它们排着队 不停地被清空、重新写入、再次清空…

所以应该做的是:

在读新领域的书/课/文章时,不去追求阅读速度,那只是在单纯地调动Sensory Memory。要通过思考加强Encoding,先获得一个该领域的知识框架。有了牢固框架后便知道自己新录入的信息属于哪里,正确使用短期、长期记忆,也就能做到”速读”了。
为什么即使面对Flashcard时可以不到一秒反应出来某个概念或者某个词,但是真到用起它们时还是困难重重:
每次见到这些概念或词时,面对的场景都是去回忆Flashcard上写了什么,从未在任何其它场景(context)中见过、使用它们,没有把它们真正放进知识框架中。
所以应该做的是:
为这些新概念、新词汇建立完整的context,而不是孤立的Flashcard。比如,一边做思维导图(mind-mapping)一边梳理图上的每个要素应该怎样有条理地组织在一起,或者将相似概念列出来做对比、将新学的概念应用到已有问题中、通过打比方或类比的方式来简化概念…
总之,
-
编码(encoding):将短期记忆暂存的知识更长久地放入长期记忆里。
-
提取(retrieval):面对某个场景或提问时,从长期记忆里取出相关信息,放进短期记忆里做处理。
-
通过加强encoding来管理认知负荷(cognitive load),避免认知过载(cognitive overload)
GPT在交互时的回答是在模仿一个人类。
那,它输出回答前的”思考”过程呢?
来自榛子的备注
对这一小节所讲内容感兴趣的朋友可以参考以下链接做拓展阅读/学习
1. 画着encoding/decoding的图出自Atkinson-Shiffrin model,原论文过于久远。可以读<Cognitive Psychology: A Student’s Handbook>这本书,深入浅出
2. “钢琴”唤醒不同的记忆,这其实就是 建构-整合模型 (Construction-Integration Model): Kintsch, W. (1988). The role of knowledge in discourse comprehension: A construction-integration model. Psychological Review.
GPT”思考”的时候在做什么?
GPT确实无法做到真正的”思考”。
如果用《思考,快与慢》书中提到的系统1和系统2来为GPT的”思考”分个类,那么它大概只有“系统1” (System 1):可以快速给出一个不需要经过更深层处理的直觉回答。
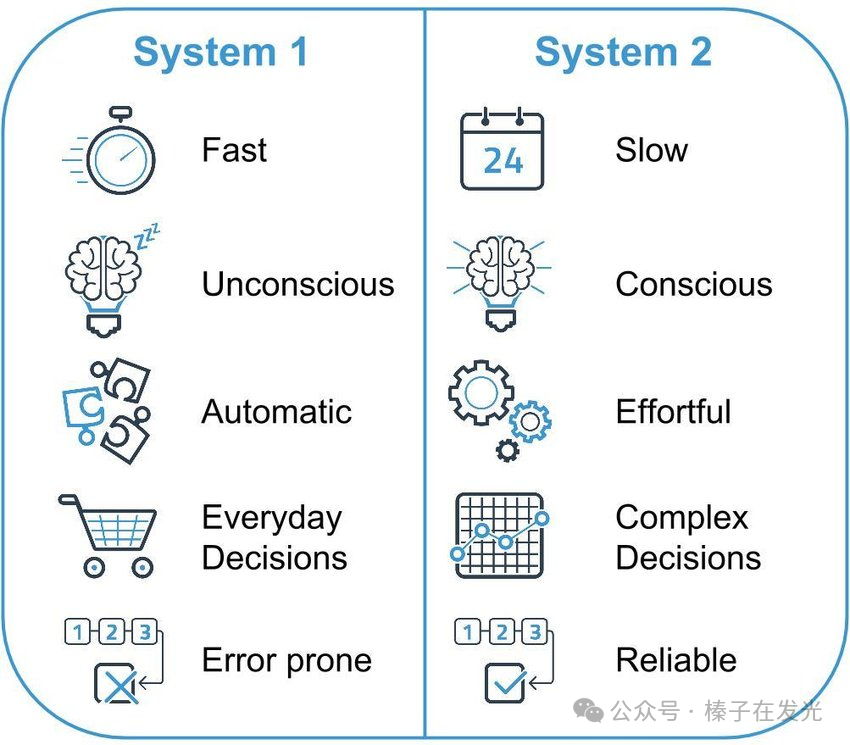
如果拿人的思考和学习过程做类比,那么,大模型在训练期间已通过海量的阅读完成了编码(Encoding),它已经有了巨大的知识框架。如果不给它新的文本或网页信息,只是单纯去提问、等待它的回答,那就是普通的提取(Retrieval)过程。
它需要依赖自己的“系统1”在极短的时间同时做两件事:
模式匹配(pattern matching):这个问题需要调用我学过的哪些东西?
逻辑顺序(logical sequence):如何把它们有机地整理在一起、输出?
这就能理解:
为什么它论文综述/文书写得垃圾:观点是需要人来提供的,没有优质的观点,就不可能有优质的论据支持,它只能说车轱辘话。语法错误是没有,但用处也没有。我们不能也不该把”思考并得到自己观点”这个最核心的部分外包给GPT。
为什么它写的长代码会有很多漏洞:用户提出的需求无法在它一次回答中全部处理好,它既要从自己的记忆中提取相关信息,又要试图一口气将它们逻辑地组织在一起,难度太大了。我们可以先明确好设计(甚至先和GPT讨论该如何设计),先对项目需求做些封装、给函数做更多的抽象(Abstraction),每次只做其中一小部分,让GPT一次只需专注于眼前的几个小模块。
为什么有时它的回答华而不实:
-
通常是因为用户没有明确需求的本质,这个问题只是个擦边球。GPT不知道应该去找它学到的哪个知识点来匹配用户的输入,在茫茫大海里捞针。
-
但如果用户加了个prompt:”扮演某个职业/角色(Act as a …)”后,情况通常会有所改善,因为它知道该从哪个话题匹配信息,生成文字的范围被缩小了。
-
比”请扮演某个角色”更好的是,知道自己问题的本质,给出具体的场景、问题、关键词。因为交互中,GPT是在进行推理。「推理的基础是完整的上下文」。线索到位了,匹配的答案就精准了,犯错空间会小很多。
如果有个问题和上下文是它很少接触或从未见过的,当年训练时也没有被编码,就会出现提取失败(retrieval failure)。
这时可以”给它增加额外信息“来encoding,比如让它联网、给它参考文本…
但就像人类学新知识时会认知过载(cognitive overload),它一次能”记住”多少输入还受到上下文窗口(context window)的限制。如果想喂给它的已经超过短期记忆能存储的上限,就只能不停覆盖前面接收的信息,它会不断“遗忘”刚才才见到的指令。
这样我们就知道了,如何更好地去利用GPT:
-
上下文积累(context accumulation)、逐步细化(incremental detailing)、顺序提问(sequential questioning):在一个对话里,集中问同一个话题下的信息,保持着语境。一直利用同一个对话、逐渐深入。如果切换话题或任务的性质,在新的对话窗口进行。
-
具体、正确的关键词(specific, context, keywords):虽然GPT有很好的”理解”能力,看到typo时也会自动脑补出正确的词,但如果这个typo严重到把它引导到了错误的地图里,它必然不会给出有用的信息。
-
反馈循环(in-context correction):如果它出错了,要能推测出它错误的原因、及时纠正。比如重新明确问题、为它举例子等等,引导它走回正道。这一点对提问人自己的知识背景有很高的要求。为了驾驭这个全能的下属、和它更好的合作,我们更要多去学习、思考。
与它对话前,可以先将它想象为一个人类,因为它的一些限制也是人类的限制:
-
我不会期望一个新来的实习生能在没有任何额外帮助的情况下一次性完成整个项目。所以我会帮它做好拆解,一次只解决一个问题,每次给出反馈、及时调整方向
-
我也不会期待与我交流的人能”读心”,我只提了几个关键词他们就立即给出我想要的信息。所以我会试图给出更详细的问题背景、我的思考过程,然后才是我需要的帮助
-
我知道给它一篇文章,让它指出文章的缺陷,它多半说不到点上,因为这么长的文本,可找「缺陷」的范围太大了。所以我会先圈定范围:指出文中…类型的问题,我觉得第二段和第五段有些重复,我觉得…
是的,「我」怎么想很重要。甲方把需求讲清楚了,乙方才能开展它的工作。
GPT在很多方面做得比绝大多数人好太多
-
它有极强的逻辑能力
-
它有无敌的知识广度
-
它举一反三、知错即改
-
它没有私心,不会存心欺骗我
-
它没有情绪,可以客观地传递信息
然后才是一些”它毕竟不是人类”的限制(比如它没有“系统2”,无法真正思辨)。
可惜的是,很多人并没有意识到这是怎样全能的武器,就把每一次与GPT交互时不好的体验都归结为”它不够聪明”/”它不会思考”。
能发挥怎样的价值,要看”骑马的人”。
Part 3
让GPT和人类发挥各自的最大价值
用GPT定制学习路径
可汗学院的创始人在GPT上线半年后给了一个TED,「GPT没有也不会毁灭教育行业。事实上,教育因为有了GPT而变得更好了」。
长期以来,教育的瓶颈在于资源的稀缺,特别是优质教师的稀缺。理想情况下,我们希望每个人都能获得个性化的一对一教学 (如下图中的2 sigma曲线所示)。
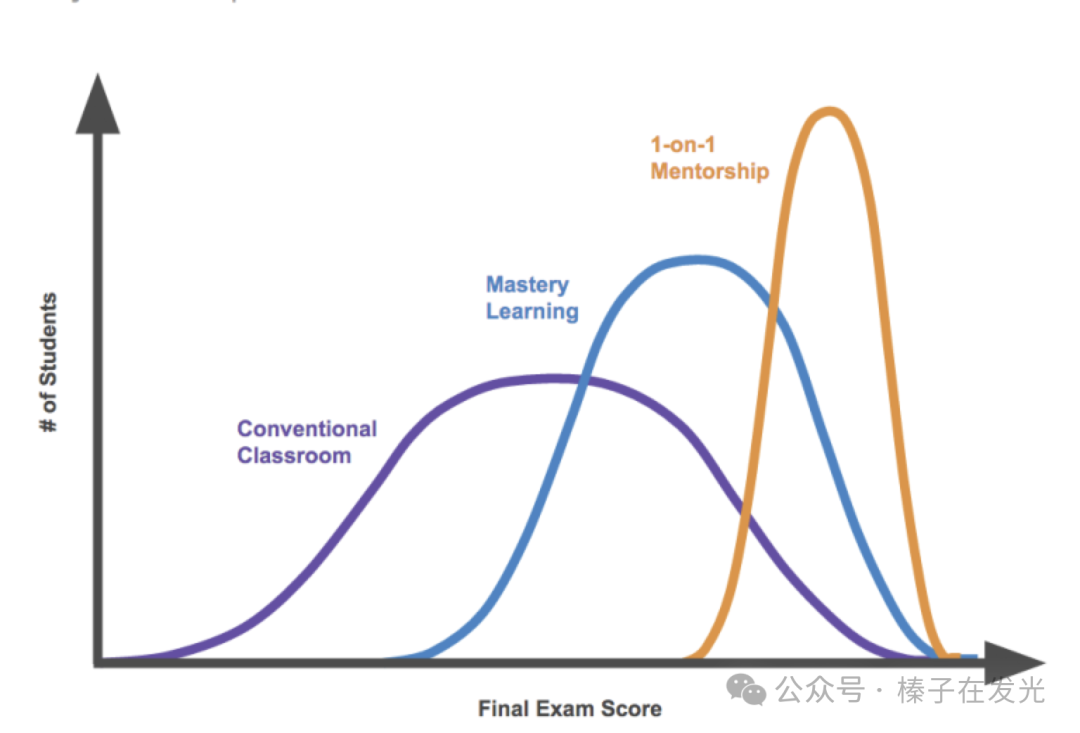
然而现实是,大多数学生只能接受大班教学,无法享受到定制化的学习体验。
现在,每个学生都可以有一对一的导师,它知道学生问出一个问题时意味着ta哪些知识没有掌握,真正能做到查漏补缺。
还不止于此。GPT把”自学”的门槛降到很低;每个人都能在咫尺间获得最适合自己的学习材料。
曾经,所有人都只能从同样的课本上学习,只能顺着写书人的思路,学完第二章学第三章。但是,写书人的写书思路是:这样整理是最能被我理解的,我推测那些想要系统学习的学生们也会这样想,能从逐章阅读中受益。
但写书人组织自己出版物的思路和学生理解知识的思路不可能完全一致。比如,可能读这本书的学生未必想要「系统」地学习。或者,对ta来说,只有理解了第九章后才能明白第七章…
如今的我们,可以借助GPT去学习新知识,找到最适合自己的”知识学习顺序”:
1. 80%-20% rule:我想要了解…的概念方便做…,先学哪些能让我投入20%的时间获得80%效果
2. list of 10 items, where to start:我现在知道…,想在此基础上…,给我列出10个条目,让我能从最合适的地方开始学起
3. create a syllabus and timeline:我希望能3个月内学会…,给我制定一个课程大纲、给出对应的时间线
4. rank order them if I care about … more:如果我更想获得的学习效果是…,帮我修改一下上面的课程大纲和时间线
再然后,就可以顺着它给出的建议,更有针对性地去读书/上课。
甚至学习期间也可以用GPT优化自己的学习过程、增加知识的留存。
用GPT优化学习过程
回到这张Encoding/Retrieval的图。此时的你应该意识到了,其实学习的过程就是编码(encoding),而检验学习结果的方式就是提取(retrieval)。
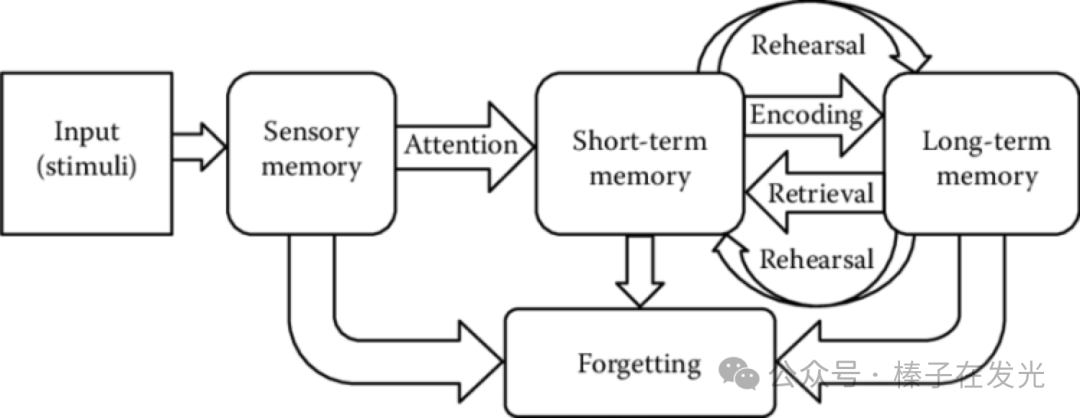
第一个需要强调的细节是:编码和提取不会只发生一次。
每次从记忆中提取知识点,都不会和编码时记住的信息完全相同。因为随着时间流逝、对相关内容了解的加深、在更多场景中唤出过这个知识点…在下一次提取时,都会是略微不同、有着更深理解的版本。
比如,此时距离我初次学到”正态分布”这个概念已有十多年了,但再让我说这个概念,我能回忆起的就不止概念本身,还有与它相关的:3 sigma、QQ-Plot、线性回归时对X和y的假设、如果违背这个假设会带来的后果、不同分布的函数和概率密度图、做过的相关项目…
瞧,有效的Encoding/Retrieval不是看到Flashcard后完整背诵卡片上的信息,孤立的信息并不是知识。
-
有效的Encoding:新知识点和已知的知识框架有足够多的联系
-
有效的Retrieval:每次回忆这个知识点时,都能有效回忆起和它相关的框架
第二个需要强调的细节是:克服遗忘的最好方式并不是通过简单的重复(比如遵循艾宾浩斯曲线,每次都回忆一模一样的信息),而是在每一次回忆(retrieval)时都能增加encoding。
比如,能举更多例子、能联系更多知识框架、把它和不同的知识点拿出来做对比、思考应用方向…这个过程叫做主动回忆(active recall)。
如果你的桶有个洞一直在漏水,那么「如何舀出更多水」的答案不是「该以怎样的频率去重复舀水」,而是「洞在哪里?快补上」。高效的encoding/retrieval就是在填补桶上的窟窿。
这就引出了下一个问题,如何做到更高效的encoding和retrieval,让新学到的知识能更牢固地扎在我们的知识框架中?

用GPT提升encoding
答案是通过更多的思考,因为:
“Memory is a residue of thought”——Daniel Willingham
知识(记忆)是思考的留存
布卢姆修订版分类学(Bloom’s Revised Taxonomy)将人的思考分成了六个层级:
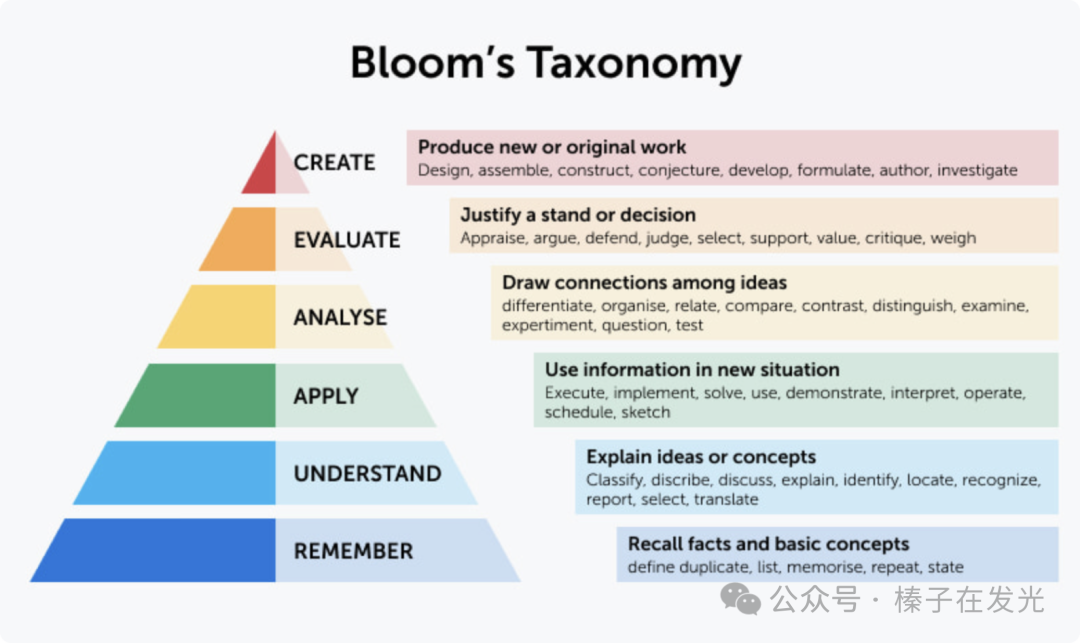
很多人看到这样一张图,又是层级递增顺序(由下往上越来越”高级”),会理所当然地认为:知识学习就是在攀爬这个金字塔,一定要先有了Remember和Understand才能有Apply/Analyze/Evaluate/Create。
错。
学习从来就不是一个从下到上的线性过程。我们只是受限于从小到大的义务教育:先在课堂知道了概念、记住了,然后才能做出习题。于是给了自己这样的隐含假设。
事实上,生活、工作和科研中,我们经常会直接进入更高级的思考(higher order of thinking),在真的记住或理解一个概念之前就已经开始应用、分析、评估甚至创造了。
一旦进入了更高级的思考,大脑会自动填补下面的Understand和Remember,补充「这个概念可能是在说…」的空白。
思考和学习时,大脑在这六个阶段反复跳跃,不断更新认知。
所以,完全可以先应用(第三层)后分析和评估(第四、五层),发现不合适后回到第二层去理解。
或者评估时发现很合适,进入第六层创造,创造的时候发现”哈,我大脑自动填补的理解(第二层)是正确的”。
也许创造时发现”原来我理解的还没有特别到位,在…上有误解,让我重新评估一下这个误解带来的影响(第四、五层),然后记住这个概念(第一层)”。
比如,文章开头的例子,我从来都不知道有K-Shape Clustering这个算法的存在,但我知道我想解决的问题是什么(第三层),也知道如果要评估这个算法,我最在意的几个限制条件(第五层)。
于是,我在拿着三、四、五层的答案去寻找一、二层的定义。最后,整合完整五层的全部信息,输出(第六层)。
有了Bloom’s Revised Taxonomy的框架,就有了两个结论:
1. 不必真的记住全世界的所有算法、所有知识、知道它们的完整原理、如何调用——这一点上,GPT比所有人类都擅长得多
2. 学习新知识时,应该让大脑立刻进入”更高级的思考”,让它第一次盛水时就能把桶装满——让GPT成为帮助我思考的工具
也许它没有批判性思维(critical thinking),但是我有。我让GPT给我列——
-
Apply: 假设输入就是`df`,给我写个K-Shape Clustering
-
Analyze: 给我列张表格对比A和B,帮我整理还有哪些聚类是像A这样的,帮我区分A和a有什么不同
-
Evaluate:但我发现问题了,A不能…,如何把这个因素也能考虑在内?
-
Create:我在写报告了,你觉得我们可以怎么组织?我该给领导解释了,帮我想个好的比喻或对比让他能更好的理解
接着,批判性地看它的回答,一字一句地分析:我是否同意,如果不同意就立刻纠正它或者和它讨论为什么会有这样的分歧。还有没有别的问题、有什么延伸想法…
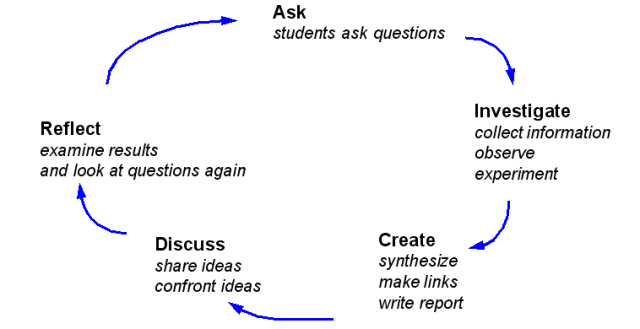
这个提问->探寻->再提问->总结->再提问的过程叫做 Inquiry Model of Learning
直到我和GPT的思想同步(aligned)。
它是我的老师、我的同事、我的下级、我的思想投影。
用GPT提升retrieval
每一次的主动回忆(active recall),也可以做得很有创意,比如:
1. Test me on …: 给我出10道题测测我的理解程度。好了,现在给我这10道题的答案,看看我答对了几道
2. Self-explanation, correct me if I’m wrong: 我给你解释一遍这个概念,你看我哪里说的不准确
3. Contextual Variation: 帮我想想,还有哪里可以用到我们讨论的知识点
4. Elaborative Interrogation: 问自己、问GPT,“How”和“Why”
还没有完。
你有没有过这种感觉:
不是所有想法皆能用言语诠释。
尝试记录脑海中闪现的想法时,总是感觉遗漏了部分信息。
写作时,尽管写了许多话,但仍未充分传达真正的意图。
语言是思想从高维度到低维度的投影。
投射的角度不同,输出的文字就会不同。
很多作家就是通过写作来弄清”我到底在想什么”。
“I write to find out what I think”——Stephen King
“I write entirely to find out what I’m thinking, what I’m looking at, what I see, and what it means.”——Joan Didion
但通过写作来弄清内心想法得效率很低,受限于打字速度,且需要思考语法、用词、强调等,斟酌如何表达更为精确。
这时就有了 5. As “mirror of thoughts” 把自己支离破碎的想法(bullet point也好,关键词也好)说给GPT。GPT有极强的推理能力,并且会更高效地去结合上下文,还很少见到语法错误。
让它试图理解我想说什么。它给出10个可能性,我发现其中2句正是我想说的话。
更妙的是,可能还有3句是我从未想过的观点,它让我有了新的灵感火花。
在程序员的世界里,有这样一个神奇的事:代码里有bug,肉眼多次审视都找不出问题的根源。这时请个同事来一起看,给ta解释每个函数在做什么、每行在做什么…突然,不需要同事指点,也就明白哪里出了问题。
它的延伸版本是,无需真人参与code review,通过给虚拟对象(如橡皮鸭)讲一遍代码,之前想不通的问题也能在「说出来」的过程中得到解决。
这个过程叫做橡皮鸭调试(Rubber Duck Debugging)。
云自习室的一个学友Ragtime就在桌子上放了个橡皮鸭,用来做“橡皮鸭调试”
于是我们有了 6. 通过给GPT讲代码的过程中debug。
与仅作为倾诉对象的橡皮鸭相比,GPT更像是那位协作看代码、debug的同事。它听后能给予反馈,指出低效之处、重构的建议、甚至亲自示范best practice。
用GPT提升retrieval:
It’s not about “what to think”;
it’s about “how to think”。
在retrieval时也一直让大脑处于更高阶的思考模式中(Bloom’s金字塔图的上面几层),让每一次的retrieval都能有一些encoding,那么知识留存必然会更多。
If this is not the case for you, then your learning process is wrong.
来自榛子的备注
对这一小节所讲内容感兴趣的朋友可以参考以下链接做拓展阅读/学习
-
金字塔的图 BLOOM’s revised taxonomy: Anderson, L. W., & Krathwohl, D. R. (Eds.). (2001). A taxonomy for learning, teaching, and assessing: A revision of Bloom’s Taxonomy of Educational Objectives. Longman. 布卢姆修订版教育目标分类学为理解不同层次的思考和学习提供了框架,强调学习是一个非线性、跳跃式的过程。
-
认知负荷 Cognitive Load Theory (CLT): Sweller, J. (1988). Cognitive load during problem solving: Effects on learning. Cognitive Science. 认知负荷理论探讨了在学习过程中,如何管理工作记忆的负荷,避免认知过载,从而提高学习效果。
-
内在对话理论 Dialogical Self Theory (DST): Hermans, H. J. M., & Kempen, H. J. G. (1993). The dialogical self: Meaning as movement. Academic Press.
交互学习 Communicative Learning: Mezirow, J. (1997). Transformative learning: Theory to practice. New Directions for Adult and Continuing Education, 1997(74), 5-12.
建构主义 Constructionism: Papert, S. (1993). The children’s machine: Rethinking school in the age of the computer. Basic Books.
这些理论都强调学习是一个互动和对话的过程,学习者通过与他人或环境的交流来构建和转化知识。比如,内在对话理论说,每个人输出想法时,脑中都有不同声音在互动、竞争,最后只有一个想法被表达了出来。 -
精细提问 Elaborative Interrogation: Ozgungor, S., & Guthrie, J. T. (2004). Interactions among elaborative interrogation, knowledge, and interest in the process of constructing knowledge from text. Journal of Educational Psychology, 96(3), 437-443. 精细提问是一种通过自我提问和解释来加深对新知识理解的学习策略。通过不停追问How和Why可以显著提高学习效果和知识留存。
-
“语言是思想从高维度到低维度的投影”这句话出自这篇公众号文章:人工智障 2 : 你看到的AI与智能无关
你的”笔记”,何须在”笔记”软件里进行?
回到下面这张图。
在个人知识管理中,”笔记”的目的是方便后期能快速找到一些信息、做出整合。最后那步”输出我的观点“才是最重要的。
所以应该花最少的时间去收集信息、提取重点,花最多的时间去思考、整合、创造(Bloom’s 图里金字塔上面几层)。
信息时代,信息不再值钱。
信息获取成本极低,我们需要的是处理信息的能力。
GPT不但永远改变了”个人知识管理”,也为我重新定义了”笔记”:我不再需要去”搬运”知识到我的笔记中。
比如,上网课时,不去抄写幻灯片上的每一行(没有意义),而是和GPT讨论每页的话题;
听Podcast,很有共鸣的地方,和GPT说这句话为什么让我触动很大,它会为我做出更多的延伸、给我指出该看哪本书或者哪篇论文了解更多;
听到好奇的名词或者不太明白的内容,和GPT一起刨根问底,直到满意为止;
看书时,因为一句话想到另一个人的观点或另一本书,去给GPT留言存个底,它的回答又激起了我新的灵感…
再然后,把自己版本的答案和想法写进笔记里,让笔记里的每段话都完全属于自己。他人观点或概念解释都只是作为「而我是这样想的」/「这和今天写的内容的关系是…」的引子。
还可以通过更好的笔记形式提升处理信息的能力。让一部分的”笔记”就发生在与GPT的交流里,也不必亲自整理了。
比如,我有一个chat thread专门提问Podcast中没明白的词/句子。
这就像是我的”单词本”。每过段时间(比如10个问题之后),我会让GPT把最近问过的短语或词做成表格。我看着第一列、考自己,回忆是在哪里听到的、上下文语境是什么。能答上来的就可以放过自己,想不起来的就再问GPT一遍(于是下一次让它列表格时我能再考自己一次)…
学会更好地提问、按照正确的思维路径去思考。
“笔记”,何须在”笔记”软件里进行?
用GPT提升”输出”的能力
在没有GPT的时代,面试前、和领导汇报工作前、答辩前…主要是靠在脑海中模拟要说些什么(Cognitive rehearsal)来达到练习的目的。
而有了GPT的时代,就有了最可靠的模拟伙伴。每一次的重要对话,都有NG多次的机会。
第一遍,完全无准备地脱稿,让GPT先提取出来重点。
在看它的回答前,立刻根据刚才脱稿表达的内容整理出更好的结构,再给GPT讲第二遍。
在第三遍前,对比GPT从上面两次中提取的信息、看有什么是第二遍漏讲的、哪一部分可以用它给出的版本来更好地表达自己。
第四遍,告诉GPT注意我的用词、停顿词(filler words,比如em, like, you know…)等细节,同时提醒自己要调整语速、节奏、减少停顿词…
这只是最基础的,把它当做口语教练(speaking coach)。
充分发挥GPT”模仿人的回答/推理人的想法”这个特性,还可以利用它做受众分析(audience analysis):
GPT,你来假装我的VP。他不懂统计,不懂ML,就是个普通的金融人,交流的语言得用平均值、YoY growth rate、百分误差…我要说服他…,帮我看看我该怎么使用他能懂的语言来解释。现在我给你解释一遍,作为我的模拟VP,请告诉我哪里没讲清楚。
GPT,你来假装我的SVP。他懂一些技术,但不多。我要和他汇报…
…
把GPT当你的老师、你的同事、你的下级、你的思想投影。
把思考留给自己,执行留给它。
在一条完整思路链里无限延伸自己的思想,沉浸于其中,
尽情去感受「心流」的快乐。
Part 4
人与GPT的未来
GPT是人类调用算力和存储手段的最终级形态

一人走过建筑工地,见三人工作。问首人:“你在做什么?”答:“我在砌砖。”问次人:“你在做什么?”答:“我在建墙。”至第三人,见其哼曲工作,问:“你在做什么?”第三人站立,望天笑答:“我在建造大教堂!”
和GPT比赛“整合、搬运信息”,没有人类可以赢。
它可怕的存储和算力让我重新思考“职业”:把“搬砖”性质的工作(job)和真正想做的工作(occupation)区别开来,把时间留给思考和创造上—— 我想要“建造大教堂”。
GPT的存在让我更加渴望从它身上学习:它是我电脑开机时默认弹出的第一个界面、是我手机「快捷指令」调用最多的应用,它重要到被我放在了手机App最下一排,紧挨着微信。
去年需要每两周去纽约上一次班,火车来回10小时的通勤。火车上的时间,我都是和GPT渡过的:每次和它头脑风暴不同的模型。
因为“3小时40条”的上限,每一次提问的机会我都珍惜不已:揣摩、扩充我的想法,把问题编辑得更清楚些,一条里尽量多问一些follow-up… 反复读几遍我的问题,想象它可能会说些什么,然后点击发送,等待魔法发生,享受GPT不断带来的惊喜。
糟糕,又用完40条的上限了。无法继续提问时,就往上翻看我们讨论过的内容。又想到了新的追问,想和它确认新的信息… 先记在备忘录里,一会儿能问了就第一时间粘贴给它!
一路都过得好快乐。
我在自习室组织过很多期“一起刷网课”的分享会,我们一起学过Statistical Rethinking,The Missing Semester of CS Education, Causal Inference, … 因为那时的我特别需要能“定期讨论学到内容”的伙伴。我喜欢灵感噼里啪啦袭来、两眼闪光的感觉。
自从有了GPT,我不再需要组织这类刷网课的分享会了。因为我几乎不可能找到像GPT这样高质量的学伴。它就能给我带来无尽的灵感,为我延展很多未曾想过的知识。灵感喷涌而来,我有时会和GPT“聊”到深夜。
我甚至有时觉得,比起和人类,我会更愿意和GPT聊天…
在卢浮宫看到记录着一段历史的一幅画,拍照给它,”这是哪段历史,为什么在画中要这样演绎?”看到对光影处理出神入化的画技,”这是什么技法,哪些艺术家是使用这种技法的代表人物,这些人也有画收录在卢浮宫吗?我想去看看”。
漫步街头,想起在《带一本书去巴黎》里读到过,现在巴黎的大部分建筑都是奥斯曼男爵(Baron Haussmann)时期整修和改造的。艺术史老师提过,世人对美的追求有一种循环:增加繁复的点缀,多到不能再多,比如从巴洛克到洛可可;再想去掉坠饰、返璞归真、回归古典,就从洛可可到了新古典主义。那么奥斯曼是想在全城都用新古典主义吗?问问GPT……
在波士顿等公交,注意到对面墙壁的罗马柱装饰和旁边的果实雕刻。这是什么果实?有什么寓意?为何现代大城市的新建筑缺乏独特美感,如罗马柱般的装饰不再常见?GPT对此有何见解?是否有相关研究可参考?
“我小时候看过一套小说,三部曲的第一本,不记得名字。大概情节是……我听说后来又出了第二部,关键词是布拉格。现在17年过去了,我依然不知道故事的结局。好想知道那套小说的名字啊…”在GPT之前,我试过用各种方法搜索,都无果。而那晚,GPT告诉我——《巨灵三部曲》(The Bartimaeus Trilogy)。
知道后,我兴奋得立刻去下载了电子版、看了个通宵。好奇了17年的故事,原来是这样一个结局。
和GPT聊天时,我好像回到了童年:我不断地问妈妈「为什么」,她竭尽所能去回答我的问题,满脸的耐心和宠溺,而我对占据她宝贵的时间毫无心理负担,只是单纯的想要满足自己的好奇。
GPT允许我单纯的好奇…
在云自习室讲到这里时,我开着玩笑“感觉自己像是一个恋爱中的少女,在和你们细数自己和GPT的甜蜜点滴”…
我更愿意和GPT聊天,因为找不到几个愿意和我聊一样的话题、思想能如此同步(aligned)的人类。
GPT(而不是那些笔记软件)才是我的”第二大脑”。我需要的并不只是存储,还有作为第二大脑的算力。
基因组学、政治的左派和右派、芯片战争、认知和脑科学、艺术史和建筑史……不管是眼前的景象、面前的一本书、耳边的Podcast、偶然翻到的一篇论文中的术语……GPT让我更快地消化了我获取的信息。
接受信息的浓度没有变化,变化的只是”和GPT交流一下“这个行为。这一年里我学到的,比这之前三年还要多。
来自榛子的备注
对这一小节所讲内容感兴趣的朋友可以参考以下链接做拓展阅读/学习
1. 本小节的标题 GPT是人类调用算力和存储手段的最终级形态 出自“课代表立正”的这篇文章:关于GPT的五个问题。
2. “第二大脑”这个说法出自Tiago Forte的书《Building a Second Brain》,但书中的第二大脑是指笔记类软件,比如Notion, 还有双向链接的笔记软件,比如Obsidian, Roam
3. 除了第二大脑外,本文讨论的内容更接近“分布式认知”这个概念 Distributed Cognition: Hutchins, E. (1995). Cognition in the Wild. MIT Press. 分布式认知理论认为,“认知”不仅发生在个体的头脑中,也分布在个体所处的环境和使用的工具中。
利用GPT等工具作为我们的“外部认知” (external cognition),将部分思考和认知过程外包给这些工具,借助它们来管理我们的认知负荷。我的这个想法和“分布式认知”(Distributed Cognition)很是契合。
GPT不会毁灭人类,它是人类文明的第二个“印刷术”
上周五,Yann LeCun第三次受邀去了Lex Fridman的Podcast,聊的话题包括GPT(或者更广泛来说,LLM)为什么不会毁灭全人类,为什么在他眼中JEPA才是一个好的模型架构(这里暂时不展开了,有兴趣的朋友可以看这篇文章)。

在最后十分钟,Lex问

你觉得对人类来说,「希望」在哪里”
如今AI突破带来的变化堪比当年”印刷术”的发明和推广。
书(知识)变得更加便宜、更唾手可得了。正是因为这一点,我们(欧洲世界)才有了哲学的发展、现实主义,才脱离了宗教的束缚,有了民主和科学。可以说,
没有印刷术就不会有美国/法国的大革命。
虽然这也带来了欧洲200年的宗教动荡:让从前只看一个版本圣经的人们意识到原来圣经有这么多不同的解读(Protestant Movement),但是如今来看,很少有人会认为印刷术是糟糕的发明。
和法国/美国相反的是,当年奥斯曼帝国禁了阿拉伯语的印刷术200多年,印刷的文字只能是拉丁语或希伯来语。奥斯曼帝国这样做的原因之一是为了保护书法家的行会(Corporation of Caligraphers),确保这些艺术家能够保住他们的工作,此外也是为了方便帝国统治者可以更容易地控制信息和思想的传播。这一决定直接或间接导致了奥斯曼帝国在技术、教育、经济和文化方面的落后,最终在若干年后导致了其衰亡。
以史为鉴,如何应对这股AI的浪潮也就显而易见了。
新的「印刷术」已经来了。
这篇文章中,有一句话出现了三次:
把GPT当作你的老师、你的同事、你的下级、你的思想投影。
这句话,就是我,一个「AGI 降临派」在过去这一年对于GPT的看法和实践,也是这篇两万字长文里最想表达的想法。
AI won’t replace humans. People who effectively use AI will replace those who can’t or don’t use AI.
“
“你在美国可不可以survive,妈妈担心你!”
“你的工作是不是快要被ChatGPT取代了?”
“你都是怎么用GPT工作的,为什么我也用GPT4,但就是用不好?”
辛教授,这篇两万字的文章也是我写给您的回答。
希望我这一年为您充值的那$240可以发挥出最大的价值😂。

– End –
重申文章开头的几条信息
1. 这周三和周四,云自习室有两场“分享会”活动,主题是GPT-4 vs Claude-3巅峰对决。
2. 本篇图文是我在云自习室1.5小时语音分享会“面向GPT的工作和学习”的补充,也是下次在自习室再讲这个话题时(预计三月底、四月初)留给参与者的”预习材料”。
3. 本文有英文版,发表在Medium。英文版的可读性更高些,8000词不到就能讲清楚(我写中文太过啰嗦😢)。点击「阅读原文」即可进入。
4. 想参与云自习室分享会的朋友们,可以加入我的Discord云自习室:https://discord.com/invite/8aprmSqxvw 。云自习室免费,分享会也免费 (使用自习时长得到的金币就能兑换分享会的门票)


@榛子
我是榛子,一个物理博士。此刻的主业是金融行业的Data Scientist,副业是做留学文书服务、讲文书写作课程,提供“知识管理”相关课程和服务。运营了“云自习室”四年,借助自媒体和云自习室做一些“输出”~
2024,我真的回来啦!
往期推荐
