2023年,大模型技术迎来颠覆性突破,新兴AI应用不断涌现,重塑着人类、机器与智能的关系。一场人工智能风暴,席卷世界。
为此,昆仑万维天工团队重磅推出「天工一刻」系列内容,对大模型上下游技术进行一次全面解读,涵盖学术热点、技术创新、应用案例等。
希望我们的内容能为所有关注大模型技术的读者,提供一些借鉴与参考。

对于广大用户而言,大模型的能力最直观体现在答案生成上。用户向“天工”AI搜索提问后,大模型将直接结合搜索内容生成答案,无需用户在纷繁冗杂的链接集合中亲自寻找。

但事实上,大模型在“天工”AI搜索里发挥的作用,可远不仅仅在此。
数据搜集、索引建立、检索算法设计、排序算法设计、向量数据库、检索增强生成、搜索结果生成……大模型的能力贯穿了“天工”AI搜索的几乎每一个环节。
对于用户而言,大模型加持的新一代搜索引擎,能够让搜索结果更精准、更高效、更可信;
而对于搜索引擎的设计者而言,大模型加持,能让开发人员投入更少的重复工作、更快的开发速度、得到更好的搜索效果。
本文将从以下方向介绍与AI搜索引擎相关的大模型技术:
很少人知道,搜索引擎的历史,和万维网(www)一样长。
1990年,万维网之父蒂姆·伯纳斯-李(Tim Berners-Lee)刚刚将WorldWideWeb浏览器和Web服务器的源代码发布到了互联网上,HTTP协议还要数年之后才会出现。
当时,FTP(文件传输协议)仍是网络文件共享的主要工具。但不同的FTP文件零星储存在互联网的各个角落,没有具体的文件地址就无法访问。
为了解决这个问题,三名加拿大蒙特利尔的大学生聚在一起,发明了一款用于FTP文件资源检索的工具——Archie。
使用Archie,用户只需要知道文件名称,就能够查询文件所在FTP地址。
这三名年轻人没有意识到,他们随手的一个举动,竟揭开了互联网历史上全新的一页——搜索引擎。
自此,全球第一款互联网搜索引擎诞生,互联网搜索概念迎来大爆发。
3年后,世界上第一个互联网互联网爬虫程序诞生;4年后,世界上第一个既可搜索又可浏览的分类目录诞生、基于网站索引的门户网站雅虎诞生、日后名噪一时的 Infoseek搜索引擎诞生;此后,全球搜索引擎层出不穷;8年之后,谷歌诞生。
从1990年至今,三十多年间,搜索技术已经逐渐渗透到了我们电子生活的方方面面。除了传统意义的搜索引擎外,社交软件、电商平台、视频APP、职场APP、甚至外卖APP中,搜索技术都扮演着重要的角色。
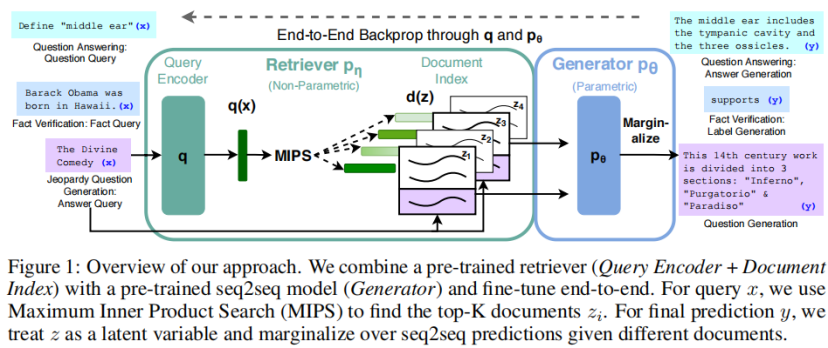
设计一个搜索引擎,大致需要以下步骤:收集及处理数据、建立索引、设计检索算法、信息匹配与排序、返回结果并呈现搜索答案。
第一步,把互联网上海量的数据(如网页、文档、内容等)收集起来,并对它们进行初步的处理。
第二步,给每个数据打上合适的“标签”,再分门别类地储存到数据库里,并设计一套精妙的检索方案,让自己随时能够找到合适的数据。
第三步,收到用户发出的搜索指令后,对该指令进行拆解分析、提取核心信息,然后把与这一指令有关的众多数据按照相关性进行排序,最终匹配呈现最佳答案。
听上去似乎不难,但如果你考虑到全球范围内究竟有多少数据,这事就远不简单了。
根据IDC Global DataSphere 2023数据,2022年,全球范围内的数据总量达到了103.66ZB,其中中国数据总量达到了23.88ZB,年均增长速度高达26.3%。
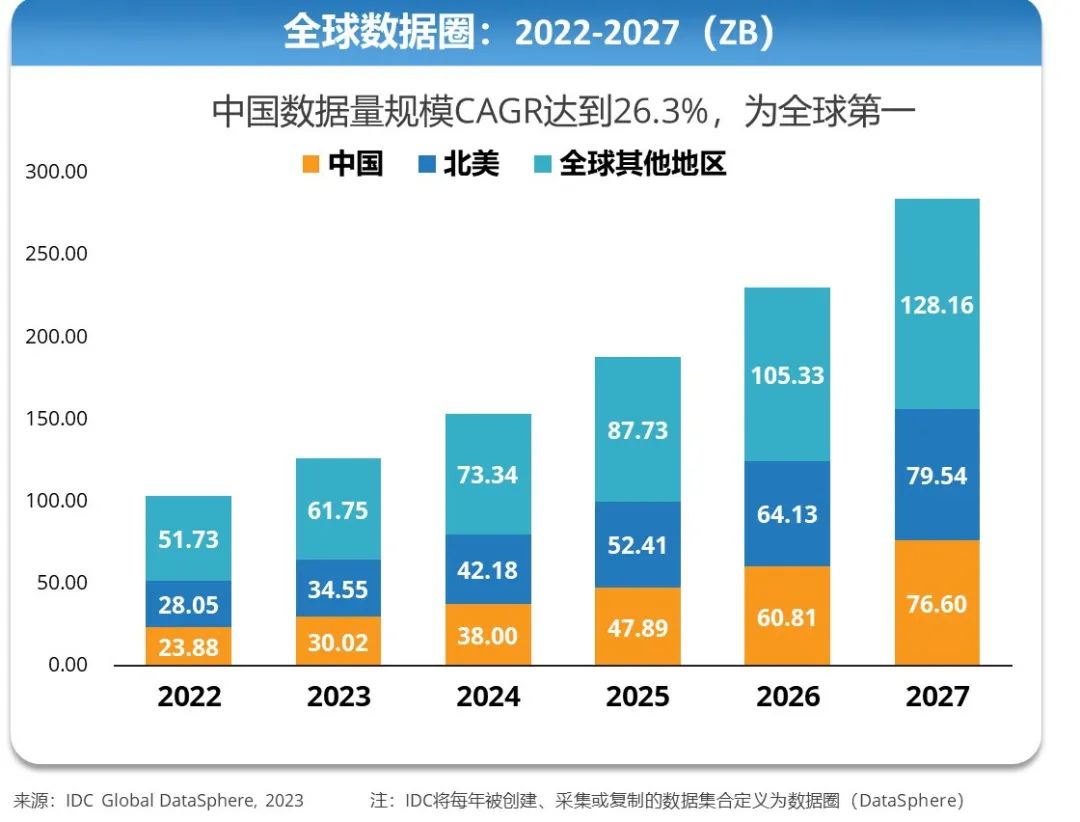
1ZB数据是10万亿亿字节,而整个地球上所有沙子加起来,大概也就56万亿亿粒。
也就是说,2022年,全中国的数据总量超过了238万亿亿字节——比四个地球的沙子加起来还多。
在四个地球的沙子里,找到一粒符合要求的沙子,难度可想而知。
自1990年至今的三十多年间,搜索技术经历了多番迭代升级,逐渐变成了一个复杂的系统性工程——涵盖数据库、索引、检索、自然语言处理、甚至计算机视觉等诸多交叉学科。
近年间,预训练Transformer模型横空出世,在人工智能领域掀起革命,此后,以GPT为代表的大语言模型(LLM, Large Language Model)席卷全球,冲击着各行各业。
首先是数据。在搜索技术的诸多环节之中,数据的收集与处理是被讨论得最少的环节,却也是最重要的环节之一。
数据收集处理之于搜索引擎,相当于地基之于摩天大楼。没有数据的积累,再好的检索算法也是巧妇难为无米之炊。
上文提到,2022年,全中国的数据总量超过了238万亿亿字节,这其中包含的可能是千亿级别的网页内容、百亿级别的音视频内容。
这其中,又充斥着海量重复信息、虚假新闻、广告内容……传统的搜索引擎需要大量的资源对这些信息进行初步的筛选与处理,但耗时长、效率低、成本高。
而在昆仑万维“天工”AI搜索的设计之初,就在数据收集与索引环节引入了大模型技术,对互联网上海量内容进行识别和筛选,屏蔽虚假广告内容,再引入网站权威性、可靠性等其他影响因子,初步清洗出较为纯净、高质量的搜索结果。
目前,昆仑万维“天工”AI搜索团队已经累计索引了上百亿优质数据资源,用户使用天工AI搜索时,将会显著地体会到搜索结果质量更高,冗余信息更少。
根据W3Techs数据,截止至2020年,全球前100万网页中,英文网站内容占比59.3%,中文网站内容占比仅为1.3%。在当前全球信息版图中,英文信息数量几乎是中文的45倍。
即便抛开中文APP的信息孤岛因素,全网英文信息数量至少也是中文的10倍以上。
特别是在人工智能、生物医学等前沿科技领域,最新、最快、最“硬核”的内容几乎全部来自英文网站。
为了解决这一问题,昆仑万维“天工”AI搜索团队在搜索引擎中引入了当今最前沿的跨语言检索技术(Cross-Language Information Retrieval,CLIR)。
利用大模型的跨语言理解能力,跨语言检索技术能够让用户在使用一种语言(如中文)查询时,搜索引擎依然能在全球范围内,深入英文知识库和学术文献进行检索,并将有用的信息翻译整合,最终生成全面、安全、准确的中文回答。
有了大模型技术“加持”,即便用户只用中文进行查询,天工AI搜索也能提供来自全球的最新信息,大大扩展了答案的知识边界。
除此之外,理解用户搜索指令(Query)也是大模型技术发挥作用的环节。
如果把搜索比作下馆子,数据处理是厨师买菜洗菜,理解用户指令是看懂用户“点的菜”,检索和答案呈现就是炒菜和上菜。
你以为用户在点菜的时候会说“给我来盘宫保鸡丁”,但实际上,用户说的往往是“今天想吃个糊辣口的东西,最好有鸡肉,要川派做法,不要京派的。最好带点甜,不甜也没关系。”
因此,昆仑万维“天工”AI搜索团队在用户搜索指令理解环节就加入了大模型技术,对用户搜索指令做Query改写,深入挖掘用户真实意图,并敏锐地捕捉到查询语句中的上下文关系,从而得到更精确、更相关、更合心意的搜索结果。
在搜索引擎的设计中,最核心的两项技术是“召回(Match)”和“排序(Rank)”。
召回指的是从数据库的全量信息集合中触发尽可能多的正确结果,并将结果返回。
排序又分为“粗排”和“精排”,指的是根据用户搜索内容的相关性,对召回结果进行排序。
在召回与排序环节里,“相关性”是最重要的目标之一。
传统搜索引擎花了海量的资源投入在“人工相关性”中,需要大量人力资源去充分理解用户搜索指令跟目标内容之间相匹配的特征、频次、距离、长短等等,几乎每个抽象算子都需要有专人去做人工分析,实时调校算法参数。
面对海量的互联网信息,这种做法必然难度大、成本高、耗时长、效率低。
昆仑万维“天工”AI搜索的召回与排序环节中,大量引入了大模型能力。
训练好的大模型能够模仿人类的识别判断能力,判断搜索指令(Query)和被搜索文档(Doc)是否具有相关性,并将这些匹配好的相关性样本当作“教科书案例”让搜索引擎学习,进而提升搜索引擎的召回、排序性能,并且实现模型侧的端对端迭代。
除了效率更高、耗时更短外,更重要的是,由于人类存在个体差异、认知差异、判断差异,即便是同一个人在不同时刻的评估结果都会有所不同。相较于人工评估,大模型能够提供更加稳定的输出结果。
除了上述对搜索技术的重塑、优化、改良外,但在更前沿的科研领域,大模型还在颠覆着搜索引擎的核心架构。
比如,在昆仑万维“天工”AI搜索中,引入了当前大模型学术界、产业界最火的研究方向之一——检索增强生成(RAG)技术。
RAG将信息检索与答案生成这两个环节结合在了一起,其技术路径可以简化理解为:用户提问——在数据库中检索相关答案——系统将用户的提问及检索出的相关答案一起合成Prompt——将Prompt提交给大模型——大模型返回提问结果。
(RAG技术原理图,来自论文《Retrieval-Augmented Generation for Knowledge-intensive NLP Tasks》)
引入了检索环节,RAG技术能够显著提高搜索答案质量,还能为答案输出提供可解释性,一定程度避免了大模型“胡说八道”的倾向。
尤其是在面对复杂的、需要深度理解的知识检索场景时,RAG技术的效果非常优秀,在准确率、召回率等关键指标上都超越了不少传统检索方法。
在海量信息面前,人类对于信息精准匹配的需求日益强烈。搜索,变得越来越重要。
大模型时代,随着各类“GPT”的不断涌现,信息检索和生成的界限日趋模糊。
2023年2月,微软发布集成ChatGPT的AI搜索引擎New Bing,2023年5月,谷歌推出试验版AI搜索引擎Search Generative Experience,2023年8月,昆仑万维推出国内第一款大模型搜索引擎天工AI搜索,越来越多的融合与变革正在发生。
在搜索引擎诞生的三十余年里,搜索技术曾不止一次地来到技术创新的奇点时刻,陈旧的体验被颠覆,用户认知被重塑。
大模型不是搜索引擎的第一次革命,也不会是最后一次。
参考资料:
1.《Retrieval-Augmented Generation for Knowledge-intensive NLP Tasks》
2.《IDC:乘数字经济之东风,顺智能转型之大势,数据云报告正式发布》
3.《LLM应用架构之检索增强(RAG)的缘起与架构介绍》
4.《前生今世——搜索引擎发展史》
●昆仑万维荣膺金牛奖最具投资价值上市公司和ESG科技引领50强两项大奖
●昆仑万维开源「天工」Skywork-13B系列大模型,0门槛商用
●昆仑万维天工通用大模型推理能力大幅超过GPT-3.5和LLaMA2,达到全球领先水平
●颜水成加入昆仑万维 出任天工智能联席CEO和2050全球研究院院长
●用大模型重塑搜索 昆仑万维发布国内第一款AI搜索产品
 论文排版软件
论文排版软件