 论文排版软件
论文排版软件
介绍
大型语言模型 (LLM) 的快速发展改变了 AI 的格局,在自然语言理解和生成方面提供了无与伦比的能力。LLM 开创了一个新的语言理解和生成时代,OpenAI 的 GPT 模型处于领先地位。这些基于大量在线数据磨练的非凡模型拓宽了我们的视野,使我们能够以前所未有的方式与人工智能驱动的系统进行交互。然而,像任何技术奇迹一样,它们也有自己的局限性。一个明显的问题是他们偶尔会提供不准确或过时的信息。此外,这些 LLM 没有提供其响应的来源,因此验证其输出的可靠性具有挑战性。在准确性和可追溯性至关重要的情况下,这种限制变得尤为重要。AI 中的检索增强生成 (RAG) 是一种变革性范式,有望彻底改变 LLM 的能力。
LLM 的快速发展将它们推向了 AI 的最前沿,但它们仍在努力应对信息容量和偶尔的不准确等限制。RAG 通过无缝集成基于检索的组件和生成组件来弥合这些差距,使 LLM 能够利用外部知识资源。本文探讨了 RAG 的深远影响,揭示了其架构、优势、挑战以及赋予其强大的各种方法。在此过程中,我们揭示了 RAG 重新定义大型语言模型格局的潜力,并为更准确、上下文感知和可靠的 AI 驱动通信铺平了道路。
了解检索增强生成 (RAG)
检索增强生成 (RAG) 代表了人工智能 (AI) 和自然语言处理 (NLP) 的前沿方法。RAG 的核心是一个创新框架,它结合了基于检索的模型和生成模型的优势,彻底改变了 AI 系统理解和生成类人文本的方式。
RAG 需要什么?
RAG 的开发是对 GPT 等大型语言模型 (LLM) 局限性的直接回应。虽然 LLM 表现出令人印象深刻的文本生成能力,但它们往往难以提供上下文相关的响应,这阻碍了它们在实际应用中的实用性。RAG 旨在通过提供一种出色的解决方案来弥合这一差距,该解决方案擅长理解用户意图并提供有意义且具有上下文感知的回复。
基于检索的模型和生成模型的融合
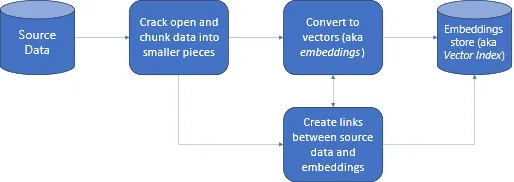
从根本上说,RAG 是一种混合模型,它无缝集成了两个关键组件。基于检索的方法涉及从外部知识源(如数据库、文章或网站)访问和提取信息。另一方面,生成模型擅长生成连贯且与上下文相关的文本。RAG 的与众不同之处在于它能够协调这两个组件,创造一种共生关系,使其能够深入理解用户查询并产生不仅准确而且上下文丰富的响应。
解构 RAG 的机制
要掌握 RAG 的本质,必须解构其操作机制。RAG 通过一系列定义明确的步骤进行操作。
-
首先接收和处理用户输入。
-
分析用户输入以了解其含义和意图。
-
利用基于检索的方法访问外部知识源。这丰富了对用户查询的理解。
-
使用检索到的外部知识来增强理解力。
-
利用生成功能来制定响应。确保回复准确无误、与上下文相关且连贯。
-
将收集到的所有信息结合起来,产生有意义且类似人类的响应。
-
确保有效地将用户查询转换为响应。
语言模型和用户输入的作用
理解 RAG 的核心是了解大型语言模型 (LLM) 在 AI 系统中的作用。像 GPT 这样的 LLM 是许多 NLP 应用程序的支柱,包括聊天机器人和虚拟助手。它们在处理用户输入和生成文本方面表现出色,但它们的准确性和上下文感知对于成功的交互至关重要。RAG 致力于通过检索和生成的集成来增强这些基本方面。
整合外部知识来源
RAG 的显著特点是能够无缝集成外部知识资源。通过利用庞大的信息库,RAG 增强了其理解力,使其能够提供信息灵通且上下文细致入微的响应。整合外部知识可以提高交互质量,并确保用户收到相关且准确的信息。
生成上下文响应
归根结底,RAG 的标志是它能够产生上下文响应。它考虑了用户查询的更广泛上下文,利用了外部知识,并生成了对用户需求的深刻理解的响应。这些上下文感知响应是一项重大进步,因为它们促进了更自然和类似人类的交互,使由 RAG 提供支持的 AI 系统在各个领域都非常有效。
检索增强生成 (RAG) 是 AI 和 NLP 中的一个变革性概念。通过协调检索和生成组件,RAG 解决了现有语言模型的局限性,并为更智能和上下文感知的 AI 交互铺平了道路。它能够无缝集成外部知识源并生成符合用户意图的响应,使 RAG 成为开发能够真正理解用户并以类似人类的方式与用户交流的 AI 系统的游戏规则改变者。
外部数据的力量
在本节中,我们将深入探讨外部数据源在检索增强生成 (RAG) 框架中的关键作用。我们探索了可用于支持 RAG 驱动模型的各种数据源。
API 和实时数据库
API(应用程序编程接口)和实时数据库是动态源,可为 RAG 驱动的模型提供最新信息。它们允许模型在最新数据可用时访问这些数据。
文档存储库
文档存储库充当有价值的知识库,提供结构化和非结构化信息。它们是扩展 RAG 模型可以利用的知识库的基础。
网页和抓取
网页抓取是一种从网页中提取信息的方法。它使 RAG 模型能够访问动态 Web 内容,使其成为实时数据检索的重要来源。
数据库和结构化信息
数据库提供可以查询和提取的结构化数据。RAG 模型可以使用数据库来检索特定信息,从而提高其响应的准确性。
检索增强生成 (RAG) 的优势
增强的 LLM 内存
RAG 解决了传统语言模型 (LLM) 的信息容量限制。传统的 LLM 具有称为“参数存储器”的有限内存。RAG 通过利用外部知识资源引入了“非参数存储器”。这大大扩展了 LLM 的知识库,使他们能够提供更全面和准确的响应。
改进的情境化
RAG 通过检索和整合相关的上下文文档来增强对 LLM 的上下文理解。这使模型能够生成与用户输入的特定上下文无缝对齐的响应,从而产生准确且上下文适当的输出。
可更新内存
RAG 的一个突出优势是它能够适应实时更新和新来源,而无需进行大量的模型重新训练。这使外部知识库保持最新状态,并确保 LLM 生成的响应始终基于最新和最相关的信息。
来源引用文献
配备 RAG 的模型可以为其响应提供来源,从而提高透明度和可信度。用户可以访问为 LLM 的响应提供信息的来源,从而提高 AI 生成内容的透明度和信任度。
减少幻觉
研究表明,RAG 模型表现出更少的幻觉和更高的反应准确性。他们也不太可能泄露敏感信息。减少幻觉和提高准确性使 RAG 模型在生成内容时更加可靠。
这些优势共同使检索增强生成 (RAG) 成为自然语言处理的变革性框架,克服了传统语言模型的局限性,增强了 AI 驱动的应用程序的功能。
RAG中的多种方法
RAG 为检索机制提供了一系列方法,以满足各种需求和场景:
-
简单:检索相关文档并将其无缝整合到生成过程中,确保全面的响应。
-
地图减少:合并为每个文档单独生成的响应,以制作最终响应,综合来自多个来源的见解。
-
地图细化:使用初始文档和后续文档迭代优化响应,通过持续改进提高响应质量。
-
地图重新排名:对响应进行排名,并选择排名最高的响应作为最终答案,优先考虑准确性和相关性。
-
滤波:应用高级模型来过滤文档,利用优化的数据集作为上下文,以生成更有针对性和上下文相关的响应。
-
上下文压缩:从文档中提取相关片段,生成简明扼要且内容丰富的回复,并最大限度地减少信息过载。
-
基于摘要的索引:利用文档摘要,索引文档片段,并使用相关摘要和片段生成响应,确保提供简洁而翔实的答案。
-
前瞻性主动检索增强生成 (FLARE):通过最初检索相关文档并迭代优化响应来预测即将到来的句子。Flare 确保了动态且与上下文一致的生成过程。
这些多样化的方法使 RAG 能够适应各种用例和检索场景,从而提供量身定制的解决方案,最大限度地提高 AI 生成的响应的相关性、准确性和效率。
RAG 中的道德考量
RAG 引入了需要仔细注意的道德考虑:
-
确保公平和负责任的使用:RAG 的道德部署包括负责任地使用该技术,并避免任何滥用或有害应用。开发人员和用户必须遵守道德准则,以保持 AI 生成内容的完整性。
-
解决隐私问题:RAG对外部数据源的依赖可能涉及访问用户数据或敏感信息。建立强有力的隐私保护措施以保护个人数据并确保遵守隐私法规势在必行。
-
减轻外部数据源中的偏差:外部数据源可能会继承其内容或收集方法中的偏差。开发人员必须实施识别和纠正偏见的机制,确保人工智能生成的响应保持公正和公平。这涉及对数据源和培训过程的持续监控和完善。
检索增强生成 (RAG) 的应用
RAG 在各个领域找到多功能应用,增强了不同环境中的 AI 功能:
-
聊天机器人和人工智能助手:RAG 驱动的系统在问答场景中表现出色,从广泛的知识库中提供上下文感知和详细的答案。这些系统能够与用户进行信息量更大、更具吸引力的交互。
-
教育工具:RAG 可以通过为学生提供基于教科书和参考资料的答案、解释和其他上下文来显着改进教育工具。这有助于更有效的学习和理解。
-
法律研究和文件审查:法律专业人士可以利用 RAG 模型来简化文件审查流程并进行高效的法律研究。RAG 协助总结法规、判例法和其他法律文件,节省时间并提高准确性。
-
医疗诊断和保健:在医疗保健领域,RAG 模型是医生和医疗专业人员的宝贵工具。它们提供最新的医学文献和临床指南,有助于提供准确的诊断和治疗建议。
-
语言翻译与上下文:RAG 通过考虑知识库中的上下文来增强语言翻译任务。这种方法可以带来更准确的翻译,考虑到特定的术语和领域知识,这在技术或专业领域特别有价值。
这些应用程序突出了 RAG 对外部知识源的集成如何使 AI 系统能够在各个领域表现出色,提供上下文感知、准确和有价值的见解和响应。
RAG 和 LLM 的未来
检索增强生成 (RAG) 和大型语言模型 (LLM) 的发展将迎来令人兴奋的发展:
-
检索机制的进步:RAG 的未来将见证检索机制的改进。这些增强功能将侧重于提高文档检索的精度和效率,确保 LLM 快速访问最相关的信息。先进的算法和人工智能技术将在这一演变中发挥关键作用。
-
与多模态 AI 集成:RAG 和多模态 AI 之间的协同作用将文本与其他数据类型(如图像和视频)相结合,具有巨大的前景。未来的 RAG 模型将无缝整合多模态数据,以提供更丰富、更符合情境的响应。这将为内容生成、推荐系统和虚拟助手等创新应用打开大门。
-
RAG 在特定行业应用中的应用:随着 RAG 的成熟,它将进入行业特定的应用。医疗保健、法律、金融和教育部门将利用 RAG 驱动的 LLM 完成专业任务。例如,在医疗保健领域,RAG 模型将通过即时检索最新的临床指南和研究论文来帮助诊断医疗状况,确保医生能够获得最新信息。
-
RAG 的持续研究和创新:RAG 的未来以不懈的研究和创新为标志。AI 研究人员将继续突破 RAG 所能实现的界限,探索新颖的架构、训练方法和应用。这种对卓越的持续追求将导致更准确、更高效和更通用的 RAG 模型。
-
具有增强检索功能的 LLM:LLM 将发展为具有增强的检索能力作为核心功能。它们将无缝集成检索和生成组件,使其更有效地访问外部知识资源。这种集成将导致精通理解上下文并擅长提供上下文感知响应的 LLM。
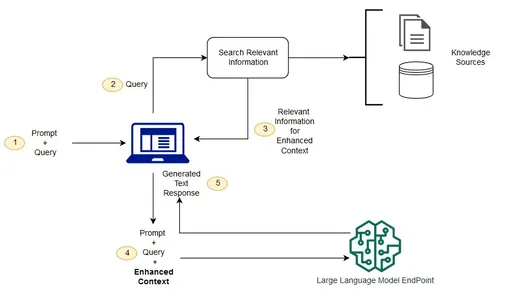
利用 LangChain 进行增强检索
—增强生成(RAG)
安装 LangChain 和 OpenAI 库
这行代码将安装 LangChain 和 OpenAI 库。LangChain 对于处理文本数据和嵌入至关重要,而 OpenAI 提供对最先进的大型语言模型 (LLM) 的访问。此安装步骤对于设置 RAG 所需的工具至关重要。
!pip install langchain openai!pip install -q -U faiss-cpu tiktoken
import osimport getpassos.environ["OPENAI_API_KEY"] = getpass.getpass("Open AI API Key:")
RAG 知识库的 Web 数据加载
-
该代码利用了LangChain的“WebBaseLoader”。
-
指定了三个用于数据检索的网页:YOLO-NAS 对象检测、DeciCoder 的代码生成效率和深度学习每日时事通讯。
-
此步骤对于构建 RAG 中使用的知识库、实现上下文相关且准确的信息检索以及集成到语言模型响应中至关重要。
from langchain.document_loaders import WebBaseLoaderyolo_nas_loader = WebBaseLoader("https://deci.ai/blog/yolo-nas-object-detection-foundation-model/").load()decicoder_loader = WebBaseLoader("https://deci.ai/blog/decicoder-efficient-and-accurate-code-generation-llm/#:~:text=DeciCoder's%20unmatched%20throughput%20and%20low,re%20obsessed%20with%20AI%20efficiency.").load()yolo_newsletter_loader = WebBaseLoader("https://deeplearningdaily.substack.com/p/unleashing-the-power-of-yolo-nas").load()
嵌入和矢量存储设置
-
该代码为 RAG 进程设置嵌入。
-
它使用“OpenAIEmbeddings”来创建嵌入模型。
-
初始化“CacheBackedEmbeddings”对象,允许使用本地文件存储有效地存储和检索嵌入。
-
“FAISS”向量存储是从预处理的 Web 数据块(yolo_nas_chunks、decicoder_chunks和yolo_newsletter_chunks)创建的,从而实现快速准确的基于相似性的检索。
-
最后,从向量存储中实例化检索器,便于在 RAG 过程中进行高效的文档检索。
from langchain.embeddings.openai import OpenAIEmbeddingsfrom langchain.embeddings import CacheBackedEmbeddingsfrom langchain.vectorstores import FAISSfrom langchain.storage import LocalFileStorestore = LocalFileStore("./cachce/")# create an embeddercore_embeddings_model = OpenAIEmbeddings()embedder = CacheBackedEmbeddings.from_bytes_store(core_embeddings_model,store,namespace = core_embeddings_model.model)# store embeddings in vector storevectorstore = FAISS.from_documents(yolo_nas_chunks, embedder)vectorstore.add_documents(decicoder_chunks)vectorstore.add_documents(yolo_newsletter_chunks)# instantiate a retrieverretriever = vectorstore.as_retriever()
建立检索系统
-
该代码为检索增强生成 (RAG) 配置检索系统。
-
它使用 LangChain 库中的“OpenAIChat”来建立基于聊天的大型语言模型(LLM)。
-
定义了一个名为“StdOutCallbackHandler”的回调处理程序,用于管理与检索系统的交互。
-
创建“RetrievalQA”链,其中包含 LLM、检索器(先前初始化)和回调处理程序。
-
此链旨在执行基于检索的问答任务,并配置为在 RAG 过程中返回源文档以添加上下文。
from langchain.llms.openai import OpenAIChatfrom langchain.chains import RetrievalQAfrom langchain.callbacks import StdOutCallbackHandler
llm = OpenAIChat()handler = StdOutCallbackHandler()
# This is the entire retrieval systemqa_with_sources_chain = RetrievalQA.from_chain_type(llm=llm,retriever=retriever,callbacks=[handler],return_source_documents=True)
初始化 RAG 系统
该代码通过将 OpenAIChat 语言模型 (LLM) 与检索器和回调处理程序相结合,建立了一个 RetrievalQA 链,这是 RAG 系统的关键部分。
向 RAG 系统发出查询
它向 RAG 系统发送各种用户查询,提示它检索上下文相关信息。
检索响应
处理查询后,RAG 系统会生成并返回上下文丰富且准确的响应。响应将打印在控制台上。
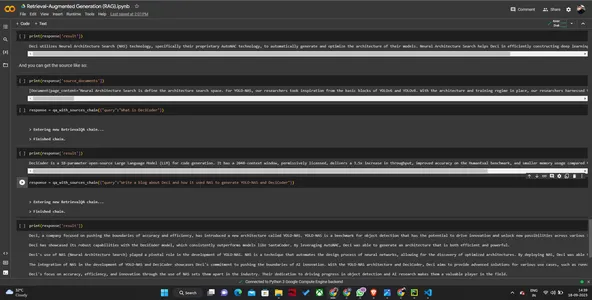
# This is the entire augment system!response = qa_with_sources_chain({"query":"What does Neural Architecture Search have to do with how Deci creates its models?"})
responseprint(response['result'])print(response['source_documents'])
response = qa_with_sources_chain({"query":"What is DeciCoder"})print(response['result'])response = qa_with_sources_chain({"query":"What is DeciCoder"})print(response['result'])response = qa_with_sources_chain({"query":"Write a blog about Deci and how it used NAS to generate YOLO-NAS and DeciCoder"})print(response['result'])该代码举例说明了 RAG 和 LangChain 如何增强 AI 应用程序中的信息检索和生成。
输出
结论
检索增强生成 (RAG) 代表了人工智能的变革性飞跃。它将大型语言模型 (LLM) 与外部知识源无缝集成,解决了 LLM 参数存储器的局限性。
RAG 访问实时数据的能力,加上改进的情境化,增强了人工智能生成响应的相关性和准确性。其可更新的内存可确保响应是最新的,而无需进行大量的模型重新训练。RAG 还提供来源引用,提高透明度并减少数据泄漏。总而言之,RAG 使 AI 能够提供更准确、更上下文感知和更可靠的信息,为各行各业的 AI 应用带来更光明的未来。
关键要点
-
检索增强生成 (RAG) 是一个突破性的框架,它通过集成外部知识源来增强大型语言模型 (LLM)。
-
RAG 克服了 LLM 参数存储器的局限性,使它们能够访问实时数据、改进上下文化并提供最新的响应。
-
借助 RAG,AI 生成的内容变得更加准确、上下文感知和透明,因为它可以引用来源并减少数据泄漏。
-
RAG 的可更新内存消除了频繁的模型重新训练,使其成为各种应用的经济高效的解决方案。
-
这项技术有望彻底改变各行各业的人工智能,为用户提供更可靠、更相关的信息。
常见问题解答
问题1. 什么是 RAG?它与传统的 AI 模型有何不同?
答:RAG 或检索增强生成,是一种创新的人工智能框架,结合了基于检索和生成模型的优势。与仅根据其预先训练的知识生成响应的传统 AI 模型不同,RAG 集成了外部知识源,使其能够提供更准确、最新且与上下文相关的响应。
问题2. RAG 如何确保检索到的信息的准确性?
答:RAG 采用从外部来源获取信息的检索系统。它通过向量相似性搜索和实时更新外部数据集等技术来确保准确性。此外,RAG 允许用户访问源引文,从而提高透明度和可信度。
问题3. RAG 可以用于特定行业或应用吗?
答:是的,RAG 用途广泛,可以应用于各个领域。它在准确和最新信息至关重要的领域特别有用,例如医疗保健、金融、法律和客户支持。
问题4. 实施 RAG 是否需要广泛的技术专长?
答:虽然 RAG 涉及一些技术组件,但可以使用用户友好的工具和库来简化该过程。许多组织也在开发用户友好的 RAG 平台,使其可供更广泛的受众使用。
问题5. RAG 有哪些潜在的道德问题,例如错误信息或数据隐私?
答:RAG 确实提出了关键的道德考虑。确保外部数据源的质量和可靠性、防止错误信息以及保护用户数据是持续的挑战。道德准则和负责任的人工智能实践对于解决这些问题至关重要。
原文地址:https://www.analyticsvidhya.com/blog/2023/09/retrieval-augmented-generation-rag-in-ai/
MO AI
添加管理员微信
加入 Mo-AI 俱乐部群聊

长按识别二维码
关注我们的公众号

发现意外,创造可能
Mo
