 论文排版软件
论文排版软件导语
随着用于文献和数据搜索的人工智能工具的发展,开发人员试图让生成和验证假设的过程变得自动化。
本文转载自集智俱乐部(ID:swarma_org),作者:Andy Extance,编译:王佳纯
计算机科学家ChristianBerger的研究团队在进行汽车自动驾驶算法研究时,遇到一个艰难的阻碍。瑞典哥德堡大学的科学家们在一篇系统的文献综述中找到了1万多篇关于这个课题的论文。Berger表示,正确地调研这些论文需要花费一年的时间。
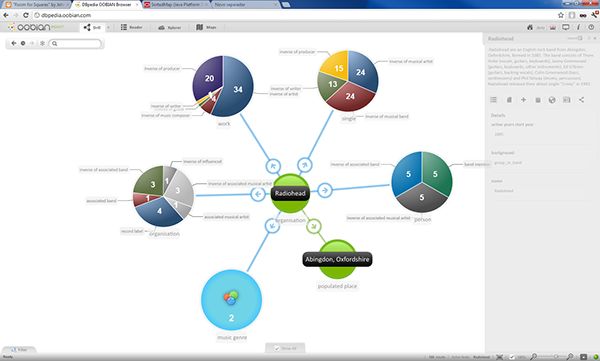
幸运的是,他们得到了Iris.ai的帮助,Iris.ai是一个基于人工智能的文献搜索工具。只要输入300-500字的问题描述或者输入现有论文的网址,这项位于柏林的服务就会返回一个地图,地图上有成千上万个匹配的文档,并且根据主题做了可视化分类。

©Iris.ai
Iris.ai是一系列基于人工智能的新型搜索工具之一,它们都提供了知识的定位导航。类似的工具还有华盛顿西雅图的艾伦人工智能研究所与微软研究院联合开发的Semantic Scholar,目前在学术界使用十分广泛。每种工具都各有特色,它们给科学家提供了查找科学文献的不同视角,不同于PubMed和Google Scholar这样的传统工具。甚至有些时候,通过揭示搜索结果之间的隐含联系,可以提出新的假设来指导实验。
semantic scholar

Google scholar
伦敦艾伦图灵研究所的数据科学家Giovanni Colavizza长期研究学术出版物的全文分析。他表示,这些工具提供了当前最先进的信息检索。传统的工具主要用作引文索引,而基于人工智能的工具可以对文献进行更深入的分析。
功能强大,也意味着这些工具通常很昂贵,并且受到它们所搜索的那部分科学文献的限制。普尔曼华盛顿州立大学的动物健康图书管理员Suzanne Fricke写过一篇关于Semantic Scholar的资源评论(S. Fricke J. Med. Lib. Assoc. 106, 145–147; 2018),他表示,这些工具不会进行全面搜索,例如,有些工具旨在让你快速了解某个话题,所以它们应该与其它工具配合使用。
Berger回应了这种观点:“只使用一个研究引擎不能自动回答每个问题。”
用科学知识训练机器
用科学知识训练机器
对于海量的科学文献,基于人工智能的”快速阅读器“非常有用。据估计,全世界每年有100万篇论文发表,即每30秒一篇。科研人员几乎不可能跟得上这样的速度,即便是在他们自己狭小的学科领域里。因此,有些人试图通过计算来解决这个问题。
这些工具所使用的算法通常有两个功能——提取科学内容和提供高级服务,如对搜索结果进行过滤、排序和分组。Colavizza解释说,提取科学内容的算法通常使用自然语言处理(NLP)技术,这项技术试图解释人类语言。例如,开发人员可以使用有监督的机器学习,这就涉及到用论文的作者和参考文献等实体信息来标注训练集中的样本,然后训练算法来识别和提取实体。

为了提供更高级的服务,算法常常构造知识图谱,详细描述实体间的关系并展示给用户。例如,人工智能表明,如果句子中提到了药物和蛋白质,那么它们之间是有关系的。Colavizza说:“知识图谱将这种关系编码为数据库中的一种显性关系,而不仅仅是文档中的一个句子,从本质上来说,这使得机器可以读取实体间的关系。”
Colavizza指出说,Iris.ai采用不同的方法,它将文档按照主题分组,这些主题是根据文档所用词汇来定义的。Iris.ai搜索连接库(Connecting Repositories ),这是一个可搜索的数据库,有超过1.34亿开放访问的论文和用户文库提供访问权限的期刊。Iris.ai的首席技术官Viktor Botev说,Iris.ai联合了三种算法来创建反映词汇使用频率的“文档指纹”,然后根据相关性对论文进行排序。
搜索结果就是一张相关论文的地图,该公司计划未来要通过识别每篇论文中提出的假设来补充搜索结果。该公司还在开发一个基于区块链并行计算的Aiur项目,该项目试图使用人工智能来对照其它科学文档检查研究论文的方方面面,从而验证假设。
Colavizza表示,像Iris.ai这样的工具可以进行免费的基本查询,有助于在粗略了解的领域对文献进行初步探索。但是如果要进行更加细致的搜索来使研究人员快速进入新领域,那每年就要花费高达2万欧元(合2.3万美元)来购买服务。
Colavizza建议,寻求更深入了解本专业的专家可以考虑使用免费的基于人工智能的工具,如Microsoft Academic或Semantic Scholar。还可以选择Dimensions,其基本功能是免费的,但搜索并分析授权数据和专利数据,以及利用可编程的维度搜索语言(Dimensions Search Language)获取数据则需付费。(Dimensions由Digital Science科技公司创建,由Holtzbrinck出版集团运营,该集团在《自然》杂志出版商也持有大量股份。)
Colavizza还表示,Semantic Scholar拥有一个基于浏览器的搜索栏,它与谷歌等引擎非常相似。但是它比谷歌学术提供了更多的信息来帮助专家优化结果。这些信息包括流行度指标、数据集和方法等主题,以及引用文本的确切摘录。“我很惊讶地发现,当一种方法或想法非常完善以至于研究人员没有提到它的起源时,这个工具也能捕捉到间接的引用。”Colavizza补充道。
Semantic Scholar的总经理Doug Raymond表示,每个月有一百万人使用Semantic Scholar的服务;Semantic Scholar使用NLP技术提取信息,同时构建联系以确定信息是否相关且可靠。
Raymond还补充道,Semantic Scholar可以识别不明显的联系,比如计算机科学的方法论与计算生物学的联系;可以帮助识别尚未解决的问题和重要的假设来验证或反证。Raymond说:“目前,Semantic Scholar从计算机科学和生物医学科学中收集了超过4000万份文档,其语料库正在增长。最终,我们希望融入所有学术知识。”
对于其它工具,比如来自德国海德堡的欧洲分子生物学组织(European Molecular Biology Organization,EMBO)的SourceData,实验数据是一个更关键的问题。 作为 EMBO 出版物《分子系统生物学》的主编,Thomas Lemberger 想用数字代表数据来使查找更加方便。
因此,SourceData研究了数字和它们的标注来列出实验中涉及的生物对象,例如小分子、基因或者有机体。然后,研究人员可以查询它们的关系,找到解决这个问题的论文。例如,搜索“胰岛素会影响葡萄糖吗”会检索出10篇论文,其中包含一篇“测量胰岛素(分子)对葡萄糖(分子)的影响”。
Lemberger说,SourceData正处于初始研发阶段,已经创建了一个知识图谱,其中包括在大约1000篇文章的撰写过程中人工进行的20000个实验。这个在线工具目前仅限于查询这个数据集,但是Lemberger和他的同事们正在上面训练机器学习算法。
SourceData团队还在研究一种针对神经科学的改进版工具,参与该项目的团队还有柏林洪堡大学神经生物学家Matthew Larkum领导的跨学科神经科学联合会。另外,马萨诸塞州剑桥的IBM Watson Health公司在八月份宣布,它将结合人工智能与来自Springer Nature的基因数据来帮助肿瘤学家制定诊疗方案。
生成有价值的假设
生成有价值的假设
在那些从事假设生成的人中,大约有20个是Euretos的客户。Euretos总部位于荷兰乌德勒支,其联合创始人Arie Baak解释说,该公司向工业界和学术界出售工具,主要用于发现和验证生物标志物和药物靶点,然而他没有透露具体价格。
Euretos 使用 NLP 技术来解释研究论文,不过相比于它整合的二百多个生物医学数据资源库,这一点是次要的。为了理解数据,这个工具依赖很多“实体”,即结构化的关键词列表,生命科学家创建这些列表来定义和连接其主题领域的概念。
Baak通过搜索一种称为CXCL13的信号蛋白来展示该工具的使用。在最终发表的出版物列表上,有”代谢产物”或”疾病”等类别。在这点上,软件界面看起来很像Google Scholar或 PubMed,都有一个有序的结果列表。但是,点击一个类别就会显示出额外的维度。例如,选择“基因”,就会列出与 CXCL13相关的基因列表,按引用它们的出版物数量排序;再次点击,则会呈现描述CXCL13和其他基因之间关系的图表。
荷兰莱顿大学医学中心( Leiden University Medical Centre,LUMC)的研究人员表明,这种方法可以产生新的假设,识别现有药物可能治疗的候选疾病。
合成生物学研究领域文献同被引聚类图
2017年12月,这个研究小组在罗马举办的“用于医疗保健和生命科学的语义网应用和工具(Semantic Web Applications and Tools for Health Care and Life Sciences)”会议上展示了其结果。他们还使用Euretos来识别一种称为脊髓小脑性共济失调3型(spinocerebellar ataxia type 3)的神经系统疾病的基因表达变化( L. Toonen et al. Mol. Neurodegener. 13, 31; 2018)。
那么,研究人员是否应该担心基于人工智能的假设生成会让他们失业?Colavizza不这么认为。他表示,假设生成是一个”非常具有挑战性的任务”,早期的改进将是循序渐进的;到目前为止所提出的假设”大多是在相对不令人惊讶的领域”。
当然,这种情况可能会改变。 但无论如何,计算机生成的假设都必须经过测试, 这就需要人类研究人员。LUMC 研究员Kristina Hettne提醒道:“在没有调查潜在证据的情况下,人们不应该直接相信那些自动生成的假设。即使这些工具可以帮助收集已知证据,我们也仍须进行实验验证。”
编译:集智俱乐部翻译组
来源:Nature
原题:How AI technology can tame the scientific literature
原文:https://www.nature.com/articles/d41586-018-06617-5
本文编辑:谢松骈
本文校对:雷 鸣

ID: IMGFDD
关注大数据前沿 | 助力产学研融合


内蒙古数据科学
与大数据学会
投稿、转载或商务合作请联系
