2024-05-01 分类:ai文献阅读
阅读(165) 评论(0)
我们不应该忽视,目前我们所处的时期科技快速发展,数据科学、人工智能,以及文献计量领域的成果,都可以给我们赋能,让文献阅读更加高效。
从 2017 年开始,我就在少数派网站上发布了一系列的文章,用图文和视频手把手教读者如何使用这些工具,帮助读者提升阅读文献和写作论文的效率。
我本想把上述内容都纳入本书,但是后来发现不大现实。最主要的一个问题是,技术更新迭代太快。我刚推荐了软件 A,软件 B 就出来了,而且软件 B 明显更加便捷高效。这时候你好不容易才学会了软件 A ,却徒劳无功,可能会嗔怪我故意误导你。即便是同一款工具,也会由于技术革新和软件升级导致界面发生变化,甚至操作的功能逻辑也随之改变。对于软件用户来说,这些快速的变化显然有益处;但对于纸质书的读者来说,这些变化就不怎么美妙了。 你可能有这样的经验,拿着一本几年前出版的 Python 教材学习编程,结果第二章的内容都无法顺利输出。你反复检查,笃定自己的操作没问题,于是陷入了深深的自我怀疑,甚至直接放弃。其实你的操作没问题,问题出在编程环境上。Python 从 2.x 版本升级到了 3.x 版本,就连最基本的输出语句都发生了语法变化,例如打印输出语句 print 后面不加括号,2.x 版本可以顺畅输出,可3.x 版本就会报错。
文献阅读辅助工具也是一样的道理。给你按照写作本书时的操作流程讲解一款工具,可能会让你在实际操作时处处碰壁,无所适从,扔下书,大声斥责王老师骗人。为了避免这种尴尬情况发生,我决定换一种讲法——从功能上对我演示和应用过的一系列相关工具做个分类梳理,给你介绍一番。如果你觉得其中某一款工具有吸引力,打算尝试一下,不妨根据最新的教程和官方帮助文档来进行实际操作。 本文会介绍的文献阅读辅助工具的主要类别包括但不限于以下内容。
首先是领域扫描。它要解决的是你初次接触某个陌生科研领域时碰到的问题——茫然不知所措。想想看,这其实和你到某个陌生的地方去旅游是一样的感受。这时候,你需要一张“地图”来指引。这张地图可能包括本研究领域的主要话题、重要论文、高影响力学者以及他们之间的关联等。
文献计量多年的发展使得上述结果的获取已经非常流程化。你从Web of Science、Scopus 和 CNKI 等网站导出数据集,然后经过软件分析就能从宏观上快速获得这些重要的知识地图了。 因为这方面的技术已相对成熟,所以可选择的工具也很多。篇幅所限,我这里只提几款我实际用过并且觉得好用的。此处必须说明,我没有提及的工具并不意味着它不好。下文不再赘述这一原则。
我推荐的第一款文献分析工具是 Citespace 。这款工具的作者是学者陈超美教授。我在撰写自己的博士论文时使用了这款工具,答辩的时候,使用它绘制出来的图形惊艳四座,还有老师在会后找我询问这款工具的使用方法。当时这款工具发布不久,学习资料还很缺乏,所以为了掌握它,我着实下了一番功夫。好在你现在想学习它,资料已经非常多,在主流视频网站上还可以搜到详细的操作教程。该工具的功能很多,也很权威,应用领域非常广阔。你将 Citespace 作为关键词,在各种中英文数据库里搜索,就可以感受到它的影响力了。
但是作为一个初学者,我并不建议你一上来就使用这么专业的工具。一方面“杀鸡焉用牛刀”,没有必要;另一方面是功能强大的工具往往参数众多,一不小心容易用错。特别是如果你对文献计量不是很了解,就更容易犯错。我工作以后,在参加硕士研究生论文答辩时,就见过有的学生因为对 Citespace 的参数不够了解,张冠李戴,后来这个学生意识到问题的严重性,只得把数据分析过程重新做了一遍,当然对论文相应部分也进行了大幅调整,甚至是重新撰写。
我更推荐初学者使用的是第二款工具,叫作 VOSviewer 。 这款工具的好处是更加简单明了、易学易用。基本上,进行几小时的训练,你就可以用它上手处理文献数据了。
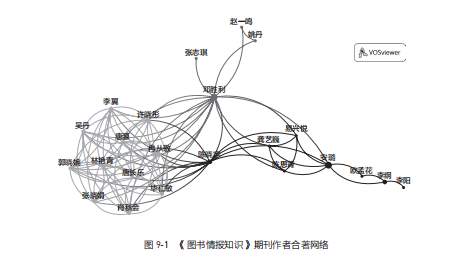
举例来说,我们从 CNKI 文献库找到《图书情报知识期刊》的数千条文献记录后,用 VOSviewer 来分析作者的合著关系。设定一定阈值后,就可以获得图 9-1 所示的网状图。
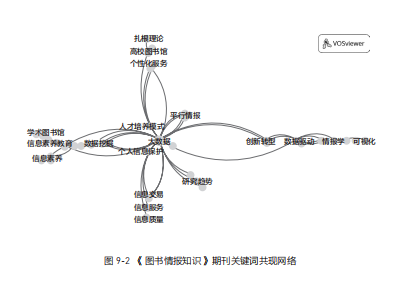
同样的文献记录不仅能研究作者的合作情况,还可以分析出关键词共现网络,如图 9-2 所示。
有了这些分析结果,你就能对某个陌生的研究领域迅速建立起初步的认知,知道哪些研究主题和研究学者比较重要,这样自己浏览和阅读文献就有了切入点。
除了 Citespace 和 VOSviewer,还有一个你可能感兴趣的文献扫描工具是 Biblioshiny 。这款工具是建立在 R 这样一个优秀的统计软件之上的,因此统计功能非常强大。
举例来说,它可以非常方便地对领域词云进行演示,做出词汇地图和主题地图等。尤其是它做的主题地图(Thematic Map)非常有意思。它以横轴代表中心度,纵轴代表密度,绘制出以下 4 个象限。
第一象限 :motor-themes,既重要,又已有良好发展(welldeveloped)。第二象限 :very specialized/niche themes,已有良好发展,但是对当前领域不重要。第三象限 :emerging or disappearing themes,边缘主题,没有好的发展,可能刚刚涌现,也许即将消失。第四象限 :basic themes,对领域很重要,但是未获得良好发展,一般指基础概念。
这些象限代表了不同主题的成熟度和重要程度,可以让你一眼望上去就对领域的发展情况知其大概。这样你在阅读文献时就可以避免在那些不重要或即将消失的主题上浪费过多的时间,反而可以在方兴未艾的潜在话题上快人一步,抓住发展趋势。
讲完了领域扫描,咱们再说说文献推荐。你可能会纳闷,领域扫描的过程中不是已经揭示文献主题和作者的重要性了吗?为什么还要专门讲“文献推荐”呢?
究其原因,是领域扫描只针对我们自行整理出的一系列文献资料进行,我们的视野被牢牢局限在手里已有的这个文献数据集内。
可我们都知道,目前跨学科融合研究是大势所趋。如果你只盯着单一领域的研究进程,可能只见树木不见森林,错失接触重要文献的机会。况且,在不同领域,人们对名词概念的界定不同。有时候你用自己想到的关键词搜索文献,返回结果寥寥,这会让你错以为这些概念没有受到关注,其实有可能别人只是使用了其他的说法而已。
可是作为科研初学者,要求你知道不同领域的概念表述,着实有些强人所难了。即便是一个有经验的研究者,在面对陌生领域时恐怕也很难把握好上述问题。文献浩如烟海,即使是专家也不可能对所有领域都了如指掌。
好在近年来人工智能的发展可以有效帮助研究者改善这种处境。
自然语言处理技术在 2018 年 BERT 模型出现后取得了很多突破。例如 GPT-3 模型已经有上千亿个参数,因此可以做出很多令人惊讶的事情——写代码、编故事等。比如你给定一段话,它就可以接着编一篇文章出来。当然这样写出来的文字,相对于人类作家所写的内容缺乏足够的逻辑。但是,GPT-3 模型的编造能力已经给社交媒体评论分析和谣言鉴别带来了很大挑战。
很多时候你真的难以分辨一段话或者一篇文章究竟是不是真人写的。
虽然 GPT-3 模型带来了破坏和威胁,但我们不能忽略它有益和有用的一面。例如一款叫作 Elicit 的文献推荐工具就是基于 GPT-3模型做出来的。
你可以直接对 Elicit 提出一个研究问题,然后它根据自己在文献领域“饱览群书”的经验,用一系列文献列表给你答案。在这些列表中,不仅有普通的文献元数据信息(例如作者、来源期刊、资助和 DOI 等),还能展现独特的智能分析结果,例如文章的类别、研究方法等。特别是对于实验类的文章,Elicit 甚至可以把样本数量、样本、年龄、区域等具体细节信息都一一自动抽取出来。靠着 GPT-3 模型的强大性能,Elicit 甚至可以在列表中根据每一篇文献综合创造新的文本来直接回答你一开始提出的研究问题。 为了避免信息过载,Elicit 一开始会给你提供一个精选的短列表。
如果你觉得其中某一篇或某几篇论文比较合乎口味,可以选中它们要求 Elicit 根据这些文献继续推荐类似的文章给你。如此,依靠 Elicit 滚雪球般的自动推荐和用户手动选择相结合的方式,你很快就能有一个精选的推荐文献列表。这比你自己手动去检索和翻阅,效率不知要高出多少。我自己带的研究生使用过 Elicit后都习惯成自然,以前的手动检索方式恐怕已无法满足他们的需求。
单从选题工作上看,重点阅读文献的哪个部分比较重要?“研究局限 ”是无法绕过的。别人尝试后还没有解决的那些问题,往往是能激发你进行后续研究的关键。以往你总要一篇篇地打开文献,找到对应的部分查看研究局限。现在有了 Elicit ,你可以直接让它分析研究局限并列在表格中一起呈现给你,这样效率就有了成倍的提升。这里多嘱咐一句,本书反复强调千万不要看到别人列出研究局限,你就照着这条道跑下去。 这些局限和展望可以当作入口和提示,但不能当作真路标来使用,原因我在选题篇已经详细为你解读过——高斯那样的“狐狸”不会给你留下痕迹,而很多论文的研究局限其实就是他下一篇论文的预告。
有了 Elicit ,你仿佛一下子有了自己的私人助理。它勤勤恳恳地帮你完成文献找寻、过滤和基础分析提炼等重复、机械的劳动,而你自己可以节省时间,把注意力放在更为要紧的研究环节上。
前面提到的几款工具帮助我们解决了“优先读什么”的效率问题,但是读文献还是需要你实打实地下功夫。在阅读文献的同时,你需要做笔记并保留文献元信息。毕竟将来动笔写作时,你还需要对笔记进行综合,并且对文献进行引用。
所以我们需要一款好用的文献管理工具来帮助我们保管文献元信息、全文数据,以及我们所做的文献笔记。跟论文检索应用类似,文献管理工具也多种多样,常见的包括 Endnote、Mendeley 和 NoteExpress 等,它们在功能上各具特色。其中我个人最喜欢的是 Zotero 这款文献管理工具。
我从 2008 年 12 月开始使用 Zotero ,至今已经 10 多年。相比而言,Zotero 是我使用时间最长的一款文献管理工具。Zotero 一出现就解决了当时论文写作者的诸多痛点。例如它靠着完善的插件系统支持多种文献库甚至网页的一键抓取元信息功能。后来Zotero 还不断进化,支持云解析 PDF 文件元数据,省去了很多烦琐的人工录入与校对操作。对于文献名称,Zotero 也可以根据元信息快速自动重命名。2022 年,Zotero 6.0 版本发布,有很大的更新,变得更为好用了。我个人总结出新版本的优点包括以下 4个方面。
一 Zotero 终于有了移动版 。你可以在移动设备(例如 iPad)上打开 Zotero 阅读 PDF 文件全文,并且可以用不同的颜色进行高亮标注。高亮标注的文本,可以算作对原文的直接引用。你还可以在某些页面做出批注;对于高亮标注的文本,也可以添加注释。甚至,你还可以把文献中的图片直接加入笔记。你不仅可以把图片截取出来使用,也可以框定公式,这样文献笔记的内容一下子就丰富多彩了。二 多端同步功能 。你在移动版、桌面端所做出的各种高亮标注和批注,以及对笔记的整理,都可以通过云端即时同步到所有登录同一 Zotero 账号的设备上。你可以在移动版上读,然后在桌面端整理和综合加工,形成自己论文的素材模块。如果你经常苦于自己阅读文献后笔记零碎,写作时难以找寻,或者只带着移动设备在外面时无法回顾阅读笔记,不妨尝试一下Zotero。 三 Zotero 有了更高细粒度的笔记管理 。原本文献管理的颗粒度(你可以打开参考文献列表来查看)只是到某一篇文章,最多是某一本书的页码范围。但是在 Zotero 中点击某个笔记条目就可以自动跳转到原文 PDF 对应的位置。这样你就可以快速查看某条笔记的上下文,更为方便地验证数据和资料来源,甚至不断激发新的想法。四 是写作时可以方便引用 。我们的阅读面向最终的输出结果——论文。我见过很多研究生采用手动编号的方式来处理文献列表,这会留下很多隐患,而且很麻烦。Zotero 提供了 Word 和OpenOffice 等写作环境的插件。当你需要引用某条文献的时候,只需要点击一下按钮,就可以自动生成文内引用,编号还是自动排列的。当然,在文末也会自动形成对应的参考文献列表。新插入、删除或者修改文献引用后,这些列表都会自动调整,你再也不用为手动编号而头疼了。
在《文献读不懂怎么办》 一文中,我介绍了文献阅读遇到问题时的几个解决方法,详细介绍了你可以使用的免费资源和路径,它们包括但不限于以下内容。
这些方法确实管用而且精准,但你可能会发现,每读一篇文献都要检索上述信息,需要的时间和精力成本也很高。环境和技术在变化,我们阅读文献时获取辅助信息的方法和思路也应该与时俱进。
因为有了 GPT-3 这样的大规模自然语言处理模型的加持,阅读文献时遇到不认识的名词或者无法理解作者的简单解释时,我们也不妨尝试一下技术对策。具体的方法就是,让人工智能替你阅读,然后把内容综合整理,结合上下文转换成简单清晰的语言,再反馈给你。
之前,这样的工具只是概念模型或是某篇文献里面的演示样例,但是就在 2022 年 10 月,我们看到了第一个真正可用的开放产品,它的名字叫作 Explainpaper 。这款在线工具使用起来也特别方便。只要你把文献上传,高亮标注某一个词语、短语或者段落,人工智能就会自动为你解读。不仅如此,你还可以根据人工智能反馈的结果继续追问。
因为开发者是外国人,所以它目前主要用于分析英语文献,并且用英语向你反馈。对于中文,开发者并没有特别优化。不过因为 GPT-3 模型在训练时,语料库中已经包含部分中文内容,所以即便你在阅读中文文献时遇到不认识的名词术语,也可以用Explainpaper 来获得解释,如图 9-3 所示。
注:此图仅展示界面效果,对部分无关内容进行了模糊处理。 在图 9-3 中,我们演示了高亮标注“知识管理”一词后,人工智能给出的解释如下 :
The term “knowledge management” refers to the process of organizing and making use of information and knowledge within an organization.
术语“知识管理 ”是指在一个组织内组织和利用信息和知识的过程。
怎么样,解释得还算贴切吧?Explainpaper 综合的信息来源不仅包括你上传的这篇文献中与之相关的上下文,还囊括了模型训练时的语料,这算是 GPT-3 模型“博览群书”的结果。所以有时候你会发现,明明在一篇论文里并没有对某个术语的解释,但是Explainpaper 也可以正确识别它,还能给出简明易懂的例子。
必须说明的是,目前 Explainpaper 这样的工具还有很多不足。缺乏中文解释能力只是其中一个方面,还有就是它严重依赖训练模型时用到的文本数据。GPT-3 模型毕竟是国外研究者的训练模型,并没有针对中文,尤其是对中文学术文献进行优化。我们更希望看到的是国内开发者利用咱们国产的大语言模型为中文科研用户理解论文提供更多的便利。希望这样的产品可以早日出现。
本文从领域扫描、文献推荐、文献管理和概念释义这些阅读文献的基本需求类型简要介绍了目前几款优秀的辅助工具。相信善用这些工具,可以帮助你提升科研阅读的效率。
当然,我们必须记住工具只是给我们帮忙的,并不能代替我们自己需要做的扎实严谨的工作。如果你食髓知味,并在找寻工具的道路上“ 一骑绝尘 ”,只专注于“ 磨刀 ”( 尝试新工具 ),却不用足够的时间去“砍柴”(认真读文献、做笔记),那就是本末倒置了,切忌!
本文摘选自《学术写作五步法:如何从零完成高质量论文》,有删改,人民邮电出版社·智元微库授权刊载。 原文链接:读研方法论|如何用技术手段辅助你的文献阅读
出品 | 天津科技大学研究生院官方微信公众号
图文来源:中国研究生
栏目排版:李智
审核: 朱丽丽 张娇林 崔妍
签发: 张娇林
上一篇要想论文润色不翻车,这里有一份指南
下一篇科研百宝箱“Citexs—赛特新思”快到碗里来
 论文排版软件
论文排版软件